pre:
sqlmap在处理数据的时候大量使用了自定义的AttribDict属性字典这个数据类型.
1 | # sqlmap paths |
所以有必要看看AttribDict这个类.
顺便总结一下自己不熟悉的相关知识点.
AttribDict组成:
这个类通过override了几个super method.
修改原生的dict定制成了自己项目需要的属性字典.
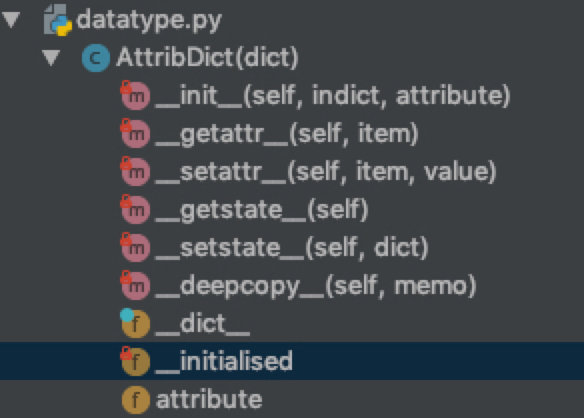
定义:
1 | """ |
原来的字典的用法:dict1["key"]
现在的自定义字典的用法:dict1.key
__init__ 初始化
1 | def __init__(self, indict=None, attribute=None): |
__setattr__ 对一个属性赋值
1 | def __setattr__(self, item, value): |
例如执行以下代码
1 | kb = AttribDict() |
kb = AttribDict()执行完,也就初始化完kb这个实例了,对象的属性储存在对象的__dict__属性中,这个时候它的__dict__为
1 | {'_AttribDict__initialised': True, 'attribute': None} |
执行kb.a=1即对实例的属性赋值的时候,就会隐式调用到__setattr__这个super method.
首先会在__dict__搜索是否初始化过的标志属性
-
如果未初始化过的话,返回一个
dict. -
如果初始化过的实例,会根据
key在__dict__搜索- 如果这个属性已经设置过的话,会调用
1
2dict.__setattr__(self, item, value)
# 相当于执行`self.itme = value`,对一个属性赋值(覆盖已有属性)-
如果这个属性没设置过的话,会调用
1
2self.__setitem__(item, value)
# 相当于执行`self[key] = val`,对新索引值赋值
__getattr__ 访问一个不存在的属性
1 | def __getattr__(self, item): |
1 | kb = AttribDict() |
执行print kb.a的时候,访问一个不存在的属性的时候,会隐式调用__getattr__这个super method.
当属性不存在的时候,__getattr__会raise an AttributeError exception.
-
默认的
__getattr__的报错:1
AttributeError: 'AttribDict' object has no attribute 'a'
-
修改过的
__getattr__的报错:1
AttributeError: unable to access item 'a'
额,效果只是让错误输出更友好而已…
__getstate__ 序列化
1 | def __getstate__(self): |
代替对象的__dict__属性被保存。
当对象pickled,你可返回一个自定义的状态被保存。当对象unpickled时,这个状态将会被__setstate__使用。
__setstate__ 序列化
1 | def __setstate__(self, dict): |
对象unpickled时,如果__setstate__定义对象状态会传递来代替用对象的__dict__属性。
这正好跟__getstate__手牵手:当二者都被定义了,你可以描述对象的pickled状态,任何你想要的。
__deepcopy__ 深复制
1 | def __deepcopy__(self, memo): |
对于简单的 object,用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
嵌套的复杂object,为了保证数据的独立性,要尽量的使用deepcopy.
好处:
kb作为一个全局的字典,保留了相关的配置信息,很多代码里都会用到这个全局的字典,暂时能想到这样的好处就是
-
大篇幅代码都用到的话,
dict1.key比dict1["key"]看起来更简洁.更pythonic. -
可以自定义更加友好的错误输出提示信息.
-
扫描中断需要继续的话,可以自定义序列化的内容,便于自己保存对象.
相关知识点:
special method:
特殊之处在哪呢?
它的特殊之处在于:
如果把Python当成一个framework的话,这些预留的特殊方法相当于接口interface.
你可以通过这些接口,使得your-object就跟built-in object高度一致,也能复用到built in-object原有的强大的功能.
有哪些类型的接口呢?
可以在以下这些方面定制你自己的类:
-
构造和初始化
-
控制属性访问
-
创建自定义容器
-
反射
-
可调用的对象
-
上下文管理
-
创建对象描述器
-
复制
什么时候会用到特殊方法呢?
原有的数据类型的功能不能满足你的要求.
例子:
-
你可以像sqlmap这里的
AttribDict在原生字典的基础上构造自己符合自己项目的数据类型. -
自带的
dict是无序的,如果你想用有序的字典.你可以用collections模块的OrderedDict.而这个OrderedDict就是在dict的基础上拓展来的.
__dict__ 对象的属性系统:
-
对象的属性储存在对象的
__dict__属性中 -
__dict__为一个词典,键为属性名,对应的值为属性本身.
来源:
-
类属性(class attribute): 类定义 or 根据类定义继承来的 -
对象属性(object attribute): 对象实例定义的
例子:
1 | class bird(object): |
1 | # bird对象属性 比如feather |
有一些属性,比如__doc__,并不是由我们定义的,而是由Python自动生成。
此外,bird类也有父类,是object类(正如我们的bird定义,class bird(object))。
这个object类是Python中所有类的父类。
可以看到,Python中的属性是分层定义的,比如这里分为object/bird/chicken/summer这四层。
当我们需要调用某个属性的时候,Python会一层层向上遍历,直到找到那个属性。(某个属性可能出现再不同的层被重复定义,Python向上的过程中,会选取先遇到的那一个,也就是比较低层的属性定义)。
当我们有一个summer对象的时候,分别查询summer对象、chicken类、bird类以及object类的属性,就可以知道summer对象所有的__dict__,就可以找到通过对象summer可以调用和修改的所有属性了.
refs: Python深入03 对象的属性
deep copy和shadow copy:
我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
对于简单的 object,用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
refs: Python-copy()与deepcopy()区别