Pre:
每处理一笔交易,就要新建一个 EVM对象 来处理交易。
EVM 对象内部主要依赖三个对象:
- 解释器
Interpreter - 虚拟机相关配置对象
vm.Config - 以太坊状态数据库
StateDB
这次先看解释器对象的源码
EVM解释器对象:
解释器对象EVMInterpreter 用来解释执行指定的合约指令。
不过需要说明一点的是,实际的指令解释执行并不真正由解释器对象完成的,而是由 vm.Config.JumpTable 中的 operation 对象完成的,
解释器对象只是负责逐条解析指令码,然后获取相应的 operation 对象,并在调用真正解释指令的 operation.execute 函数之前检查堆栈等对象。
也可以说,解释器对象只是负责解释的调度工作。
创建EVM解释器对象:
NewEVMInterpreter()函数的主要操作:
-
根据不同的以太坊版本,使用不同对象填充
cfg.JumpTable字段 -
填充
cfg.ExtraEips字段 -
生成一个
EVMInterpreter对象并返回
1 | // NewEVMInterpreter returns a new instance of the Interpreter. |
EVMInterpreter 关键方法是 Run 方法
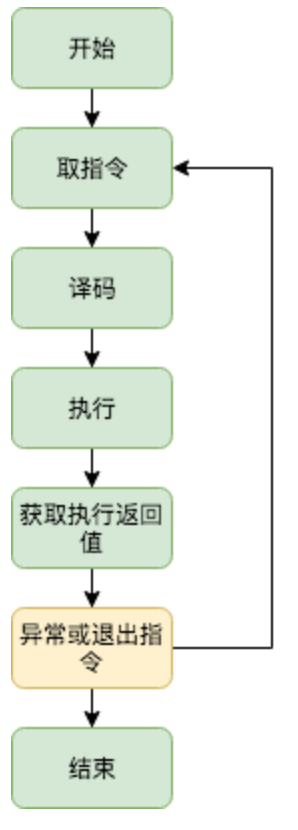
Interpreter.Run():
初始化执行循环中的中间变量:
1 | // Increment the call depth which is restricted to 1024 |
进入主循环:
-
根据
pc获取一条指令 -
根据指令从
JumpTable中获得操作码 -
检查堆栈上的参数 是否服符合操作码函数的要求
-
计算指令所需要的内存大小
-
获取这个指令需要gas消耗,然后从交易余额中扣除当前指令的消耗,如果余额不足,直接返回
ErrOutOfGas -
计算新的内存大小以动态调整内存大小,必要时进行扩容(按32字节)
-
所有使用动态内存的操作码都有动态的gas成本,扣除动态gas成本,如果不够,就返回
ErrOutOfGas错误 -
执行操作指令
-
处理操作指令的返回值
1 | // The Interpreter main run loop (contextual). This loop runs until either an |
总体来说,解释器执行循环的过程如下图:
EVM指令与操作:
我们先看下EVM模块的代码结构:
1 | evm.go // 定义了EVM运行环境结构体,并实现 转账处理 这些比较高级的,跟交易本身有关的功能 |

从上图来看:
-
opcodes中储存的是所有指令码,比如ADD的指令码就是0x01 -
jump_table定义了每一个指令对应的指令码、gas花费 -
instructions中是所有的指令执行函数的实现,通过这些函数来对堆栈stack进行操作,比如pop()、push()等。
当一个contract对象传入interpreter模块,首先调用了contract的GetOp(n)方法,从Contract对象的Code中拿到n对应的指令。
参数n就是我们上面在Run()函数中定义的pc,是一个程序的计数器。
每次指令执行后都会让pc++,从而调用下一个指令,除非指令执行到最后是退出函数,比如return、stop或selfDestruct。
1 | // GetOp returns the n'th element in the contract's byte array |
基于堆栈的虚拟机:
虚拟机实际上是从软件层面对物理机器的模拟,但以太坊虚拟机相对于我们日常常见到的狭义的虚拟机如vmware或者v-box不同,
仅仅是为了模拟对字节码的取指令、译码、执行和结果储存返回等操作,这些步骤跟真实物理机器上的概念都很类似。
当然,不管虚拟机怎么实现,最终都还是要依靠物理资源。
如今虚拟机的实现方式有两种,一种就是基于栈的,另一种是基于寄存器的。
基于栈的虚拟机有JVM,CPython等,而基于寄存器的有Dalvik以及Lua5.0。
这两种实现方式虽然机制不同,但最终都要实现:
-
从内存中取指令;
-
译码,将指令转义成特定的操作;
-
执行,也就是在栈或者寄存器中进行计算;
-
返回计算结果。
我们这里简单通过一张图回顾上面那个ADD指令的执行,了解一下基于栈的计算如何执行,以便我们能对以太坊EVM的原理有更深的理解。
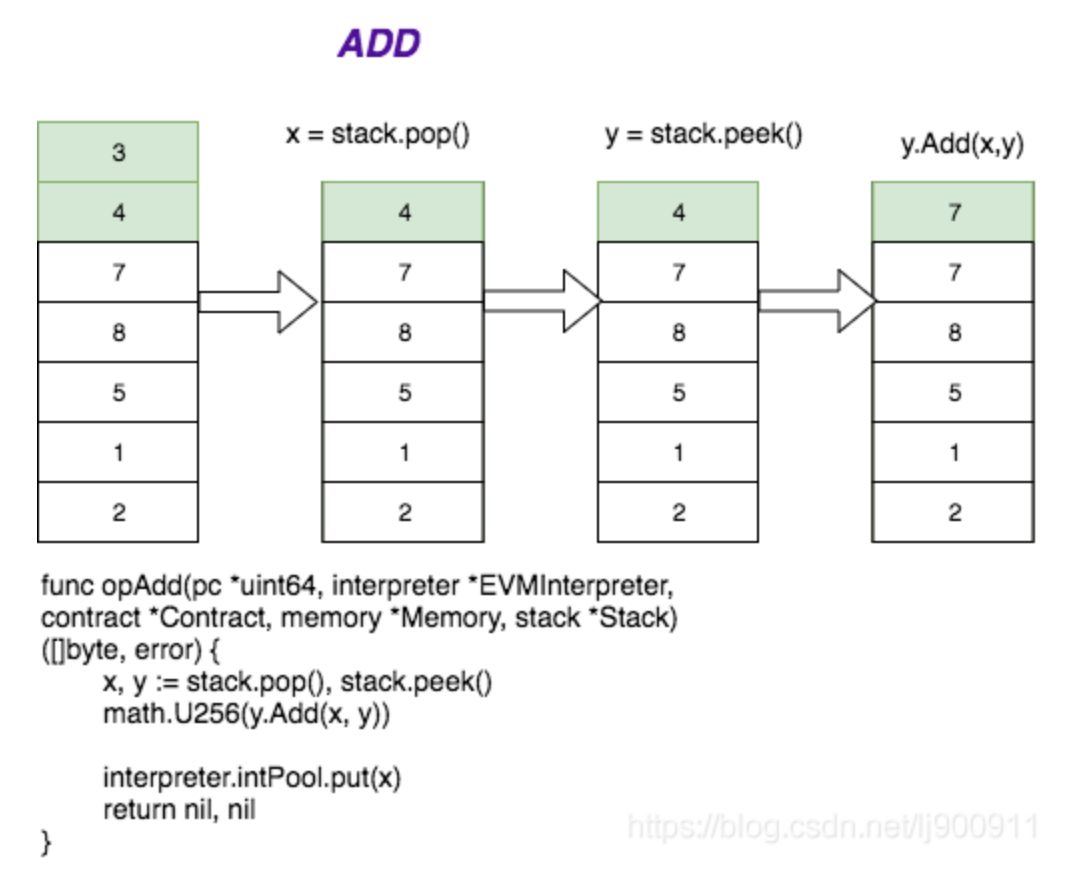
我们栈上先PUSH了3和4在栈顶,现在当收到ADD指令时,调用opAdd()函数。
先执行x = stack.pop(),将栈顶的3取出并赋值给x,删除栈顶的3,
然后执行y = stack.peek(),取出此时栈顶的4但是不删除。
然后执行y.Add(x,y)得到y==7,再讲7压如栈顶。