Pre:
潜在注入点检测:
潜在注入的检测是判断输入点是否可以成功把数据注入到页面内容
对于提交数据内容但是不输出到页面的输入点是没有必要进行Fuzzing的,因为即使可以提交攻击代码,也不会产生XSS;
在潜在注入点的检测通常使用的是一个随机字符串 ,比如随机6位数字,再判断这6位数字是否返回输出在页面,以此来进行判断。
为什么不直接使用Payload进行判断呢?
因为Payload里包含了攻击代码,通常很多应用都有防火墙或者过滤机制,Payload中的关键词会被拦截导致提交失败或者不会返回输出在页面,但这种情况不代表不能XSS,因为有可能只是Payload不够好,没有绕过过滤或者其他安全机制
所以采用无害的随机数字字符就可以避免这种情况产生,先验证可注入,再调整Payload去绕过过滤;而随机的目的在于不希望固定字符成为XSS防御黑名单里的关键词 。
— 跨站的艺术 - XSS Fuzzing 的技巧
流程:
无害字符串替换:
XSStrike采用的方式是用了作者自己的名字来作为特殊字符串.
也相当于作者的一个banner信息…
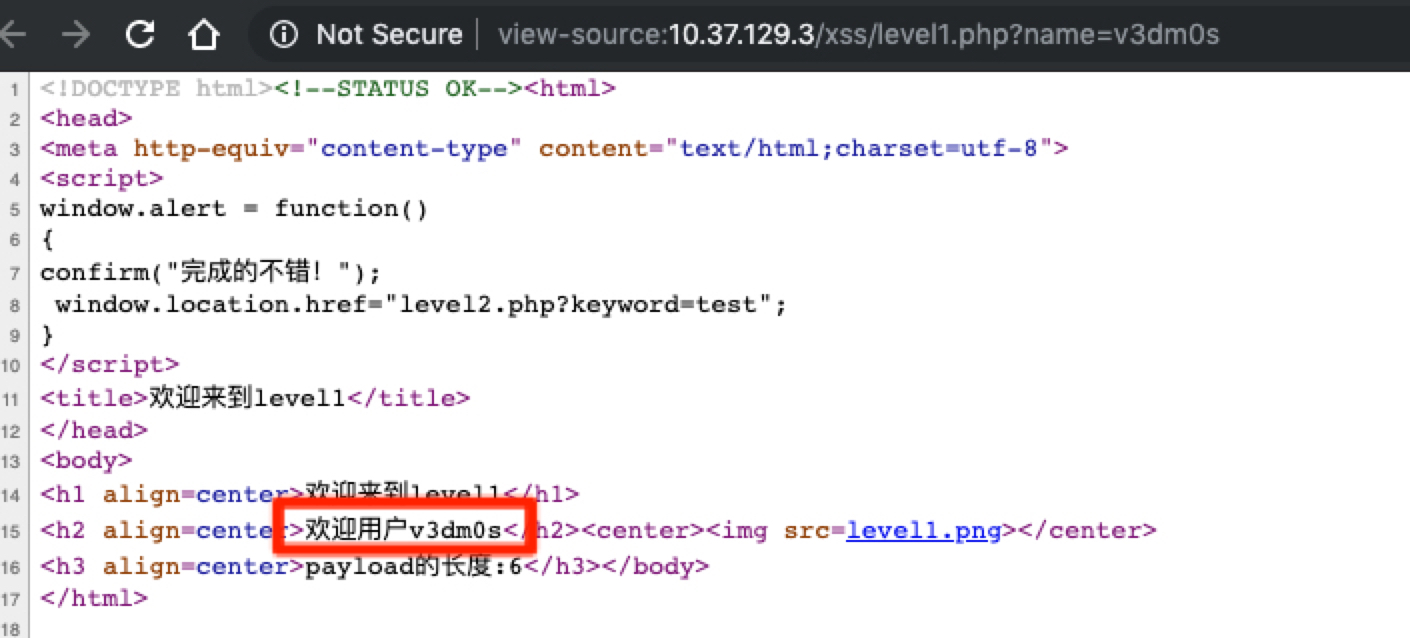
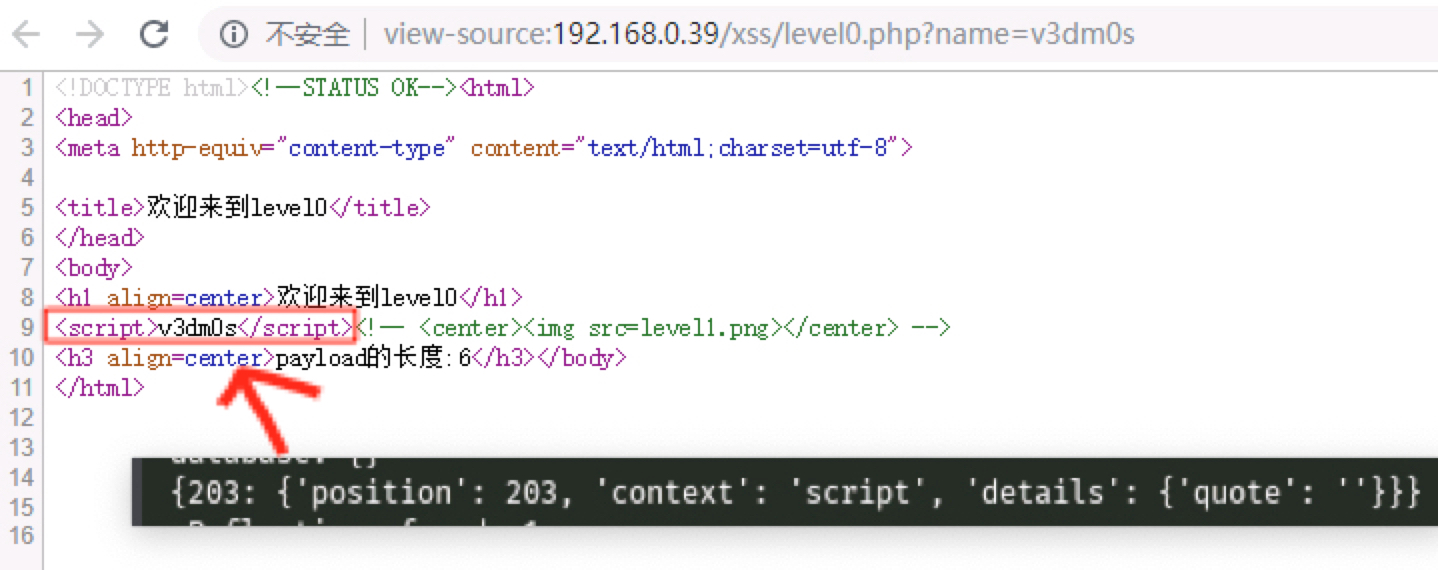
以v3dm0s去替换参数值
发包请求,在返回包源码中搜索v3dm0s
如果搜到多个地方有,那么说明可能存在多个输出点
示例:
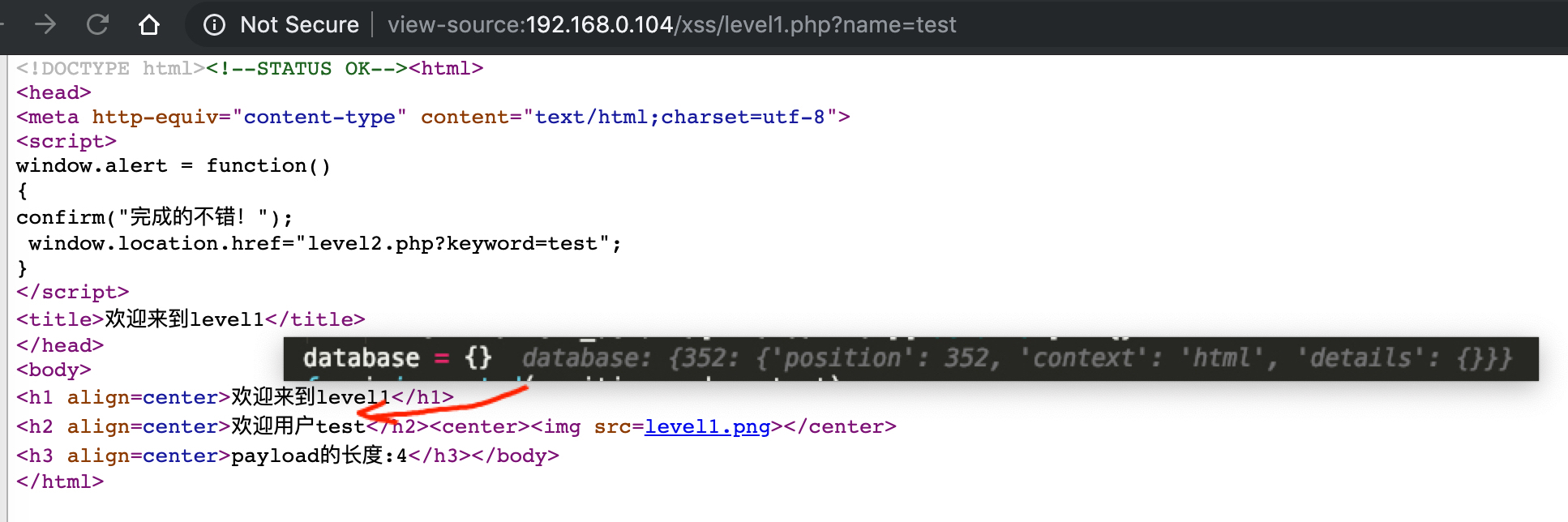
有一个初始请求url:http://192.168.0.104/xss/level1.php?name=test
将参数值test替换成v3dm0s
替换后的请求url:http://192.168.0.104/xss/level1.php?name=v3dm0s
那么说明这个页面有一个输出点.
实现代码:
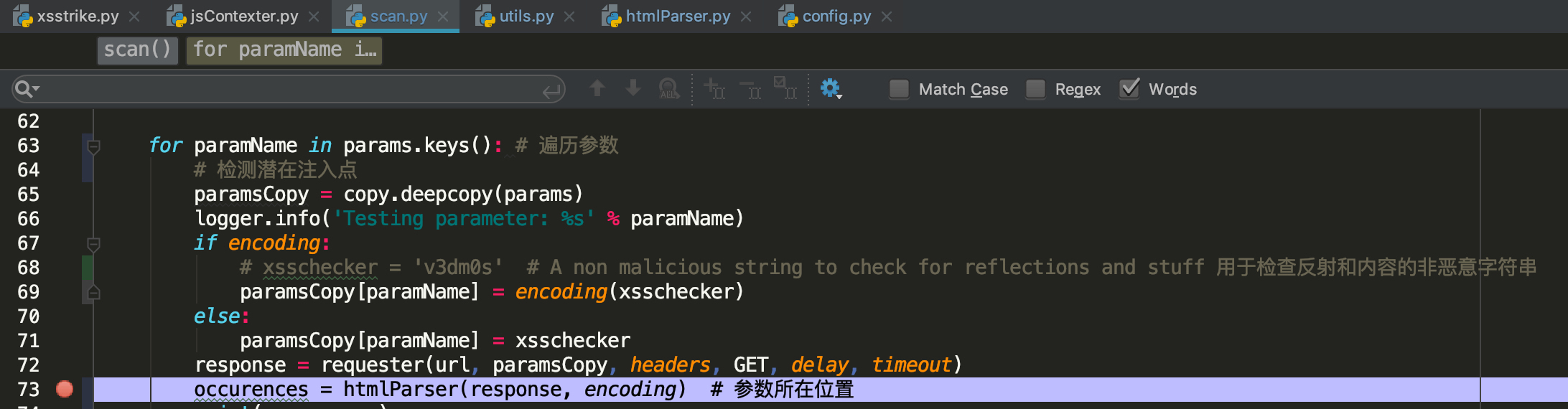
在解析完参数的前提下,进行替换.htmlParser从返回包原文解析潜在注入点(输出点)的上下文环境.
解析输出点的上下文环境:
每个输出点的环境都作为一个字典occurences存储.
1 {455 : {'position' : 455 , 'context' : 'attribute' , 'details' : {'tag' : 'input' , 'type' : 'value' , 'quote' : '"' , 'value' : 'v3dm0s' , 'name' : 'value' }}}
position:表示输出点在页面中的第几个字符处
context: 输出位置点的执行环境(script,attribute,html,comment等)
details: 执行环境的具体信息
tag: 输出点在什么标签(div,a,input等)type: 输出点是参数名还是参数值(name, value)quote: 输出点是用什么包裹起来的(单引号,双引号,`号)value: 参数值name: 参数名
输出点在script标签中:
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 for i in range (reflections): occurence = re.search(r'(?i)(?s)<script[^>]*>.*?(%s).*?</script>' % xsschecker, script_checkable) if occurence: thisPosition = occurence.start(1 ) position_and_context[thisPosition] = 'script' environment_details[thisPosition] = {} environment_details[thisPosition]['details' ] = {'quote' : '' } print ('¥¥¥¥¥¥¥¥¥¥¥' ) print (occurence.group()) print ('¥¥¥¥¥¥¥¥¥¥¥' ) for i in range (len (occurence.group())): currentChar = occurence.group()[i] if currentChar in ('\'' , '`' , '"' ) and not escaped(i, occurence.group()): environment_details[thisPosition]['details' ]['quote' ] = currentChar elif currentChar in (')' , ']' , '}' , '}' ) and not escaped(i, occurence.group()): break script_checkable = script_checkable.replace(xsschecker, '' , 1 )
小结:
主要做的就是:
判断输出点是否在script标签对里面
返回输出点在返回包原文的位置
判断输出点是用什么包裹起来的(单引号,双引号,`号)
输出点在属性中:
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if len (position_and_context) < reflections: attribute_context = re.finditer(r'<[^>]*?(%s)[^>]*?>' % xsschecker, clean_response) for occurence in attribute_context: match = occurence.group(0 ) thisPosition = occurence.start(1 ) parts = re.split(r'\s' , match) tag = parts[0 ][1 :] for part in parts: if xsschecker in part: Type , quote, name, value = '' , '' , '' , '' if '=' in part: quote = re.search(r'=([\'`"])?' , part).group(1 ) name_and_value = part.split('=' )[0 ], '=' .join(part.split('=' )[1 :]) if xsschecker == name_and_value[0 ]: Type = 'name' else : Type = 'value' name = name_and_value[0 ] value = name_and_value[1 ].rstrip('>' ).rstrip(quote).lstrip(quote) else : Type = 'flag' position_and_context[thisPosition] = 'attribute' environment_details[thisPosition] = {} environment_details[thisPosition]['details' ] = {'tag' : tag, 'type' : Type , 'quote' : quote, 'value' : value, 'name' : name}
小结:
主要做的就是:
判断输出点是否在标签里面,找出xsschecker所在的标签 如<input name=keyword value="v3dm0s">
遍历标签 如 ['<input', 'name=keyword', '', 'value="v3dm0s">']'
找出输出点的环境信息:
是在什么标签里 (如input)
由什么符号包裹 (单引号、双引号、顿号)
输出点的类型是什么?(参数名or参数值)
输出点在html中:
示例:
1 2 3 4 5 6 7 8 if len (position_and_context) < reflections: html_context = re.finditer(xsschecker, clean_response) for occurence in html_context: thisPosition = occurence.start() if thisPosition not in position_and_context: position_and_context[occurence.start()] = 'html' environment_details[thisPosition] = {} environment_details[thisPosition]['details' ] = {}
无过多处理,就是个正则匹配
输出点在注释中:
示例:
无
源码:
1 2 3 4 5 6 7 8 if len (position_and_context) < reflections: comment_context = re.finditer(r'<!--(?![.\s\S]*-->)[.\s\S]*(%s)[.\s\S]*?-->' % xsschecker, response) for occurence in comment_context: thisPosition = occurence.start(1 ) position_and_context[thisPosition] = 'comment' environment_details[thisPosition] = {} environment_details[thisPosition]['details' ] = {}
无过多处理,就是个正则匹配
标记无法执行的环境:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bad_contexts = re.finditer( r'(?s)(?i)<(style|template|textarea|title|noembed|noscript)>[.\s\S]*(%s)[.\s\S]*</\1>' % xsschecker, response) non_executable_contexts = [] for each in bad_contexts: non_executable_contexts.append([each.start(), each.end(), each.group(1 )]) if non_executable_contexts: for key in database.keys(): position = database[key]['position' ] badTag = isBadContext(position, non_executable_contexts) if badTag: database[key]['details' ]['badTag' ] = badTag else : database[key]['details' ]['badTag' ] = '' return database
在以下标签内,为不可执行的环境.
style
template
textarea
title
noembed
noscript
总结:
解析请求参数(前提)
对参数值进行无害字符串替换,发包
在返回包源码中搜索输出点
标记输出点的上下文环境
上下文环境实例:
1 {455 : {'position' : 455 , 'context' : 'attribute' , 'details' : {'tag' : 'input' , 'type' : 'value' , 'quote' : '"' , 'value' : 'v3dm0s' , 'name' : 'value' }}}
position:表示输出点在页面中的第几个字符处
context: 输出位置点的执行环境(script,attribute,html,comment等)
details: 执行环境的具体信息
tag: 输出点在什么标签(div,a,input等)type: 输出点是参数名还是参数值(name, value)quote: 输出点是用什么包裹起来的(单引号,双引号,`号)value: 参数值name: 参数名
Refs: