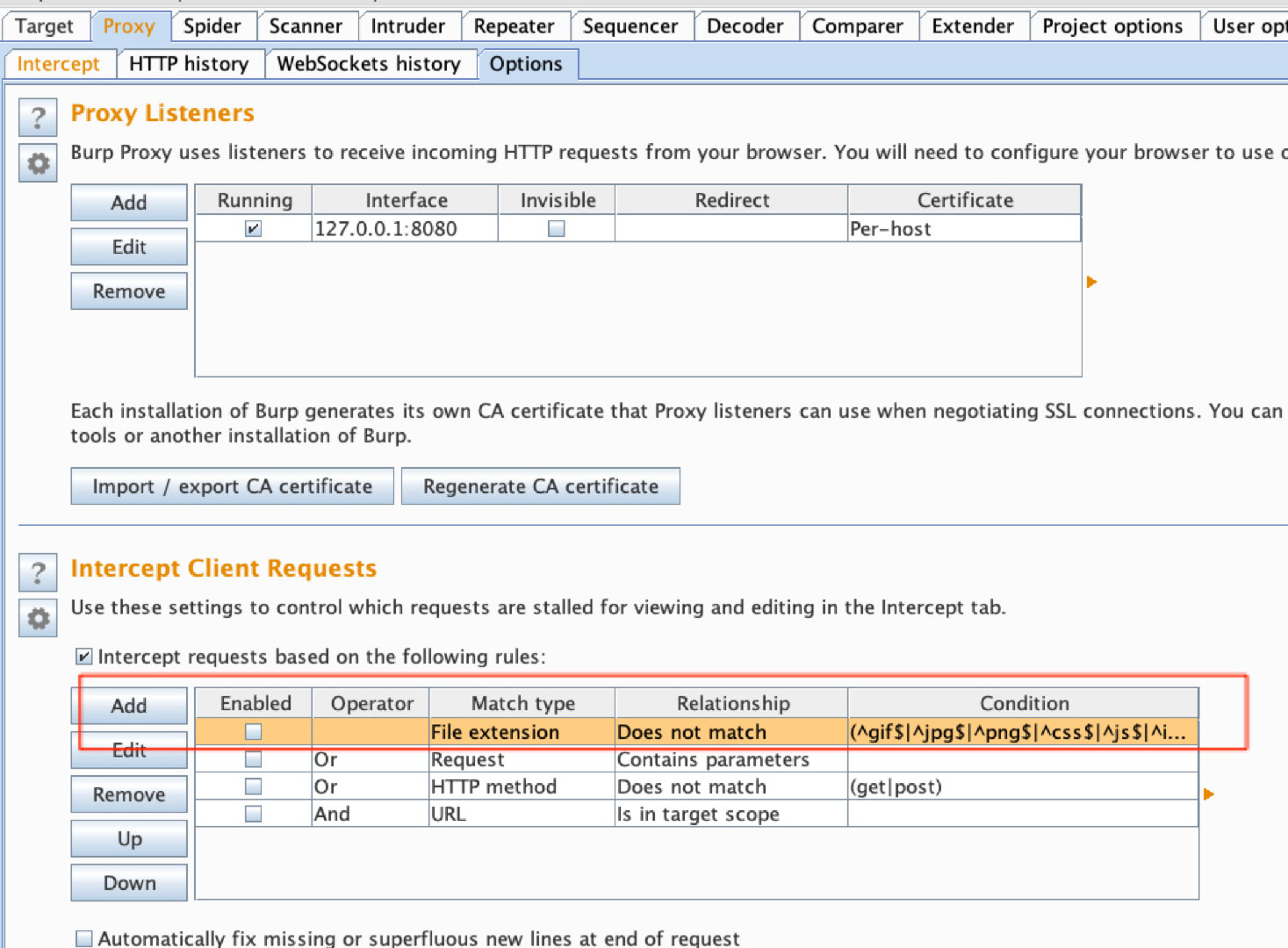
Pre:
用nyawc框架,试图爬取该urlhttp://atmos.sysu.edu.cn/里的文档类型链接的时候,发现爬取不到.
比如
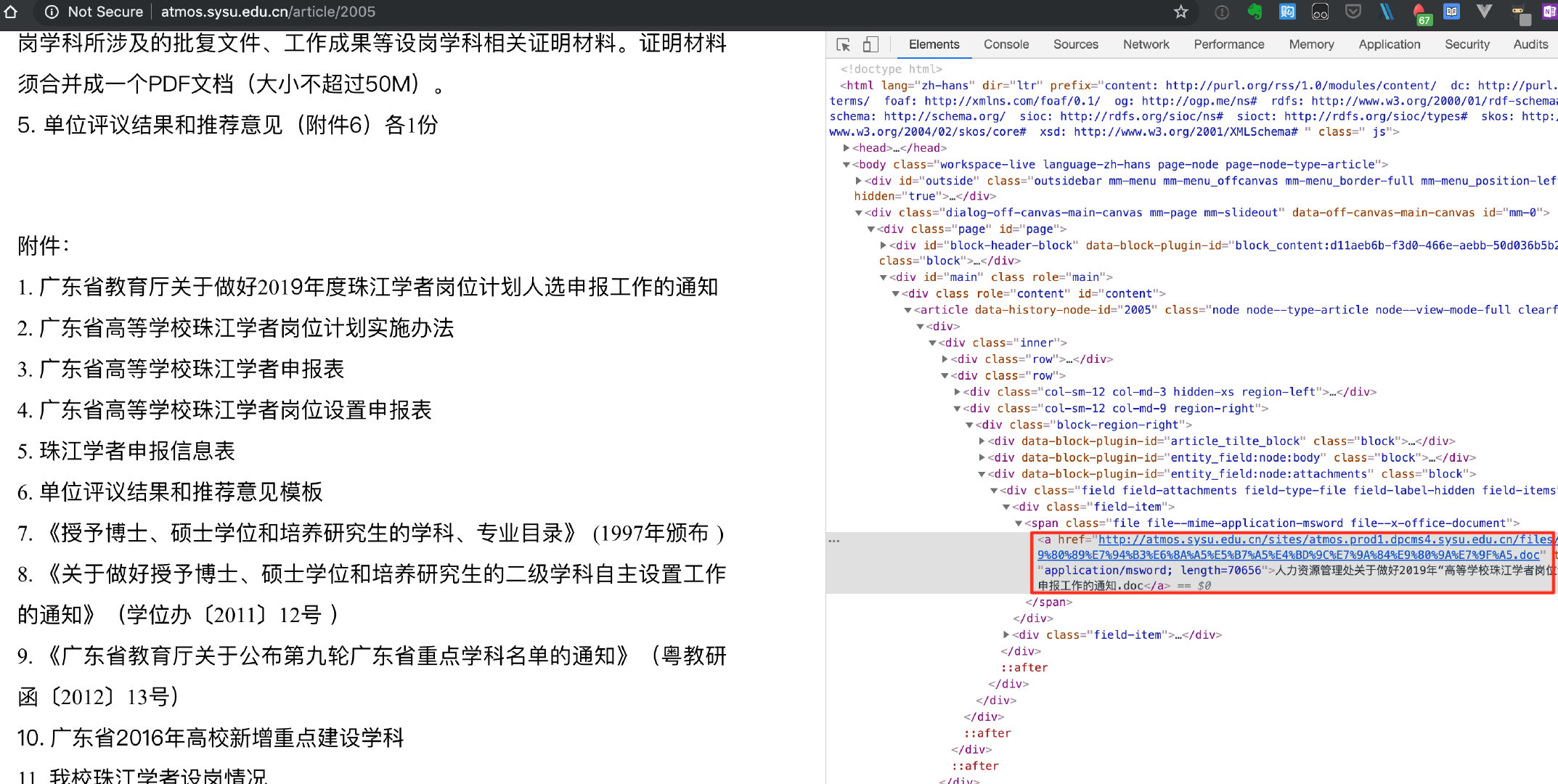
通过python模拟发包请求该urlhttp://atmos.sysu.edu.cn/article/2005
发现返回包里没有doc链接.
Debug思路1:
猜测: nyawc处理不了无后缀的url(eg.http://atmos.sysu.edu.cn/article/2005)
该网站可能是隐藏了网页的后缀.也就是对url进行了重写即url rewrite
URL重写:
什么是URL重写
如果您正在给银行写信,您可能会打开文字处理程序并创建一个名为的文件lettertobank.doc。该文件可能位于您的Documents目录中,其中包含完整路径C:/Windows/users/julie/Documents/lettertobank.doc。一个文件路径=一个文档(One file path = one document).
同样,如果您要创建一个银行网站,您可以创建一个名为的页面page1.html,上传它,然后将浏览器指向。一个URL =一个资源(One URL = one resource)。在这种情况下,资源是物理网页,但它也可以是从CMS中提取的页面或产品。
URL重写会改变这一切。它允许您将URL与资源完全分开。
通过URL重写,您可以将用户带到…/page1.html或去…/about-us/或去…/about-this-website-and-me/或去…/youll-never-find-out-about-me-hahaha-Xy2834/。或者所有这些。它有点像硬盘上的快捷方式或符号链接。一个URL =查找资源的一种方法(One URL = one way to find a resource.)。
通过URL重写,URL和它所引导的资源可以完全相互独立。
实际上,它们通常不是完全独立的:URL通常包含一些代码或数字或名称,使CMS能够查找资源。但从理论上讲,这就是URL重写所提供的:完全分离。
为什么要重写URL:
对于网站来说:
-
隐藏网站实现细节
-
有利于
SEO,复杂的url地址会对网页的收录造成影响
例如:http://www.prof…co.uk/products/brown-miniflo-gutter-148/,URL本身包含搜索词中的单词.
对于用户来说:
-
让url看起来更简洁、更容易输入和记住
如何重写URL:
是否可以在网站上实现URL重写主要取决于Web服务器
几乎所有服务器都支持,比如
-
Java可以通过web.xml配置 -
PHP可以通过模板引擎配置 -
Apache有专门的module等等
例子:
通过Apache配置的例子:
-
开启
apacheRewrite_mod模块。1
LoadModule rewrite_module modules/mod_rewrite.so
-
在配置文件末尾添加虚拟主机配置
-
新建
.htaccess文件,添加规则eg1:
1
RewriteRule ^([a-zA-Z]+)\/([a-zA-Z0-9]+)\.shtml$ $1.php?id=$2 [L]
http://www.test.test/test/3.shtml对应实际的Url地址为:http://www.test.test/test.php?id=3eg2:
1
RewriteRule ^room_(.*)$ room.php?id=$1 [NC]
http://localhost/room_123/对应的Url地址为:http://localhost/room.php?id=123
Debug思路2:
抓包分析,比较浏览器请求的包与用python模拟发的包.
浏览器抓包的实际请求:

在获取我们需要的内容(第三个包)前,必须执行一个js请求.
模拟发的包:
发现第一个包的请求的状态码是202,也就是上面图的第一个包.
结论:
这种要执行js请求才能获取得到的返回包,一般要使用无头浏览器才能解决得了.
总结:
原因:
这个问题是 发送了正确的请求,但是没有获得正确的返回结果.
获取不到预期的返回包(含doc链接),是因为在这之前还必须要有个js请求,这种请求用模拟发包一般是实现不了的,除非再花时间理解那个js文件,再模拟js的请求.
如果这样处理就会有点麻烦,一般这种情况,上无头浏览器是比较通用的解决办法.
错误的debug思路:
一开始debug的思路是不正确的,没有经过细致的排查,猜测的依据也只是根据印象,有点想当然了.
自己在调用nyawc框架的时候,是有做跟url后缀处理相关的请求.
不过这个处理只是过滤掉一些提前预设的静态url,如"gif", "jpg", "png", "jpeg", "woff", "ttf", "eot", "svg", "woff2", "ico",然后过滤掉这些url,不对这些url发送新的请求.
而我的猜测的依据 就是看到这个urlhttp://atmos.sysu.edu.cn/article/2005是个无后缀的Url,就简单猜测,并把问题定位在: nyawc处理不了无后缀的url.
这个问题定位过于宽泛了.因为
-
后缀的处理是请求前的问题
-
解析链接是请求后的问题
正确的debug思路:
-
请求前: 后缀处理是否有问题?
-
请求中: 是否请求到了正确的页面?并获得正确的返回结果?
- 一般的爬虫问题,获取不到预期的结果.最直接的办法还是比较浏览器请求的包与用
python模拟发的包 - 如果发的包不同,那就是请求前的问题.如果发的包都相同,那就是请求后处理的问题.
- 一般的爬虫问题,获取不到预期的结果.最直接的办法还是比较浏览器请求的包与用
-
请求后: 获得正确的返回结果后,是否能解析到?
改进:
-
nyawc这个爬虫框架还是有点局限的.可能后续要增加爬虫能力的话,还是要考虑上无头浏览器. -
Debug要定位问题的时候,范围不能过于宽泛.排查的步骤不能漏.要能排列组合、没有交集的列出一二三.
-
要多看源码,理解要更深入.
其他:
设置brupsuite截取js请求.