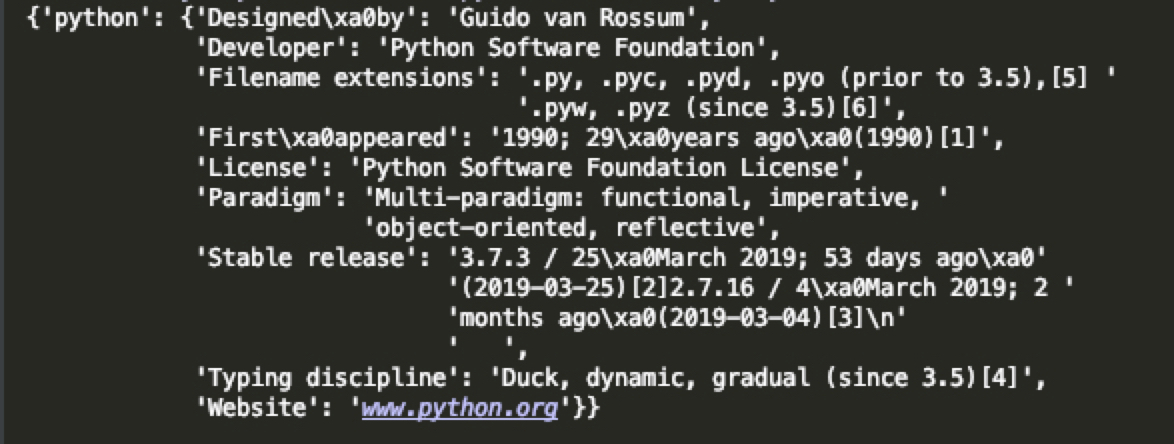
defextract_data(document): # Generate document tree tree = lxml.html.fromstring(document) # Select tr with a th and td descendant from table elements = tree.xpath('//*[@id="mw-content-text"]/div/table[1]/tbody/tr[th and td]') # Extract data result = {} for element in elements: th, td = element.iterchildren() result.update({ th.text_content(): td.text_content() }) return result
if __name__ == "__main__": languages = { "python": "https://en.wikipedia.org/wiki/Python_(programming_language)", # "Rust": "https://es.wikipedia.org/wiki/Rust_(lenguaje_de_programaci%C3%B3n)", # "Java": "https://es.wikipedia.org/wiki/Java_(lenguaje_de_programaci%C3%B3n)", # "Javascript": "https://es.wikipedia.org/wiki/JavaScript" } result = {} for name, url in languages.items(): response = get_page(url) document = read_document(response) result.update({name: extract_data(document)})
asyncdefextract_data(page): # 数据提取 # Select tr with a th and td descendant from table elements = await page.xpath( '//*[@id="mw-content-text"]/div/table[1]/tbody/tr[th and td]') # Extract data result = {} for element in elements: title, content = await page.evaluate( '''(element) => [...element.children].map(child => child.textContent)''', element) result.update({title: content}) return result
asyncdefextract_all(languages): # 程序入口 browser = await get_browser() # 启动浏览器 result = {} for name, url in languages.items(): result.update(await extract(browser, name, url)) return result
if __name__ == "__main__": languages = { "python": "https://en.wikipedia.org/wiki/Python_(programming_language)",
}
loop = asyncio.get_event_loop() result = loop.run_until_complete(extract_all(languages))