项目名:WPSIH
Website Sensitive Personal Information Hunter-网站个人敏感信息文件扫描器

项目地址:WSPIH
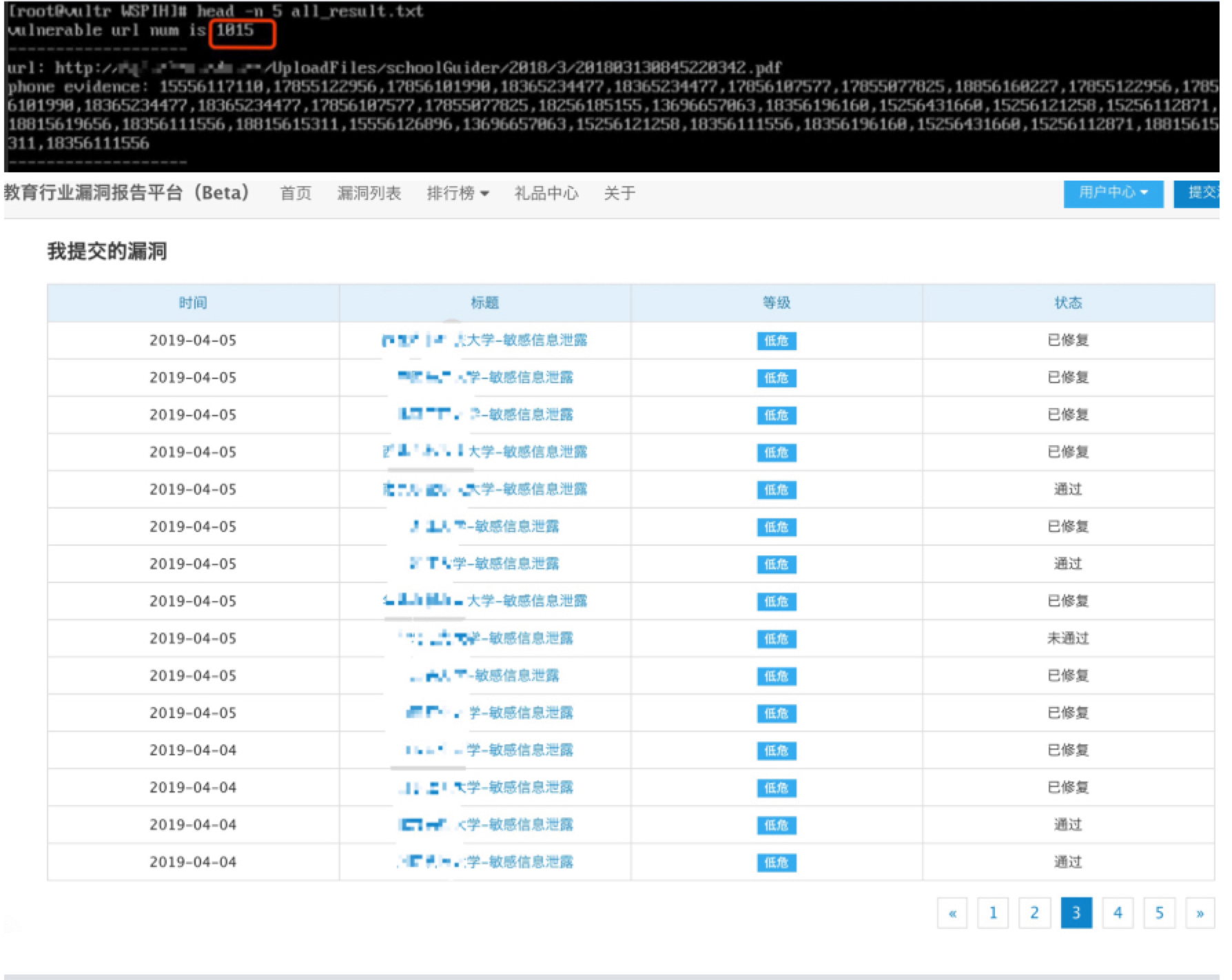
运行效果:
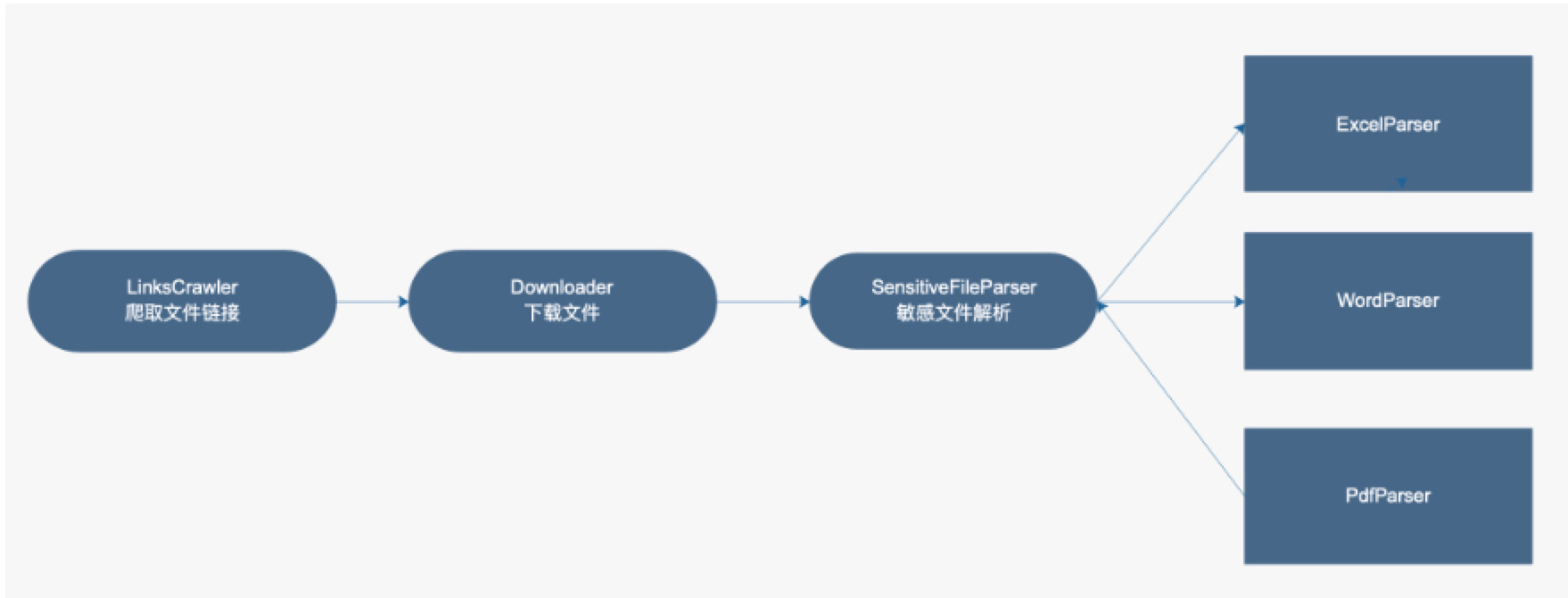
程序执行逻辑:
爬取链接:
需要过滤掉一些无用的后缀名:
1 | IGNORED_EXTESIONS = ["gif", "jpg", "png", "jpeg", "woff", "ttf", "eot", "svg", "woff2", "ico"] |
并筛选出需要的后缀名,然后保存下来:
1 | EXCEL_EXTENSIONS = ["xls", "xlsx"] |
解析文本内容:
ExcelParser:
-
使用
xlrd模块
PdfParser:
-
使用
pdfminer模块 -
无法检测图片中是否存在敏感信息;
WordParser:
-
使用
python-docx模块 -
无法检测图片中是否存在敏感信息;
-
只支持.docx
doc后缀的,需要在wins环境下转换成docx后缀,然后才能解析.遂放弃.
基于正则匹配敏感信息
1 | PHONE_REGEX = r'^(?:\+?86)?1(?:3\d{3}|5[^4\D]\d{2}|8\d{3}|7(?:[35678]\d{2}|4(?:0\d|1[0-2]|9\d))|9[189]\d{2}|66\d{2})\d{6}$' |
手机号码的正则一开始没在后面加上
$符号($是正则表达式匹配字符串结束位置),因为一开始在简单测试excel里的手机号码的时候,发现有这种情况:13424324567.0,所以唐突的把$去掉了.这种就是没有经过大量测试的后果.
导致产生了很多误报. 可见正则大法好,但是要深刻理解和正确使用.不然误报太多了.
一些有趣的点:
隐藏起来的敏感信息:
有些文件是能匹配出敏感结果的,但是实际上你去打开那个文件,你会找不到结果.举例如下:
-
excel的隐藏列:
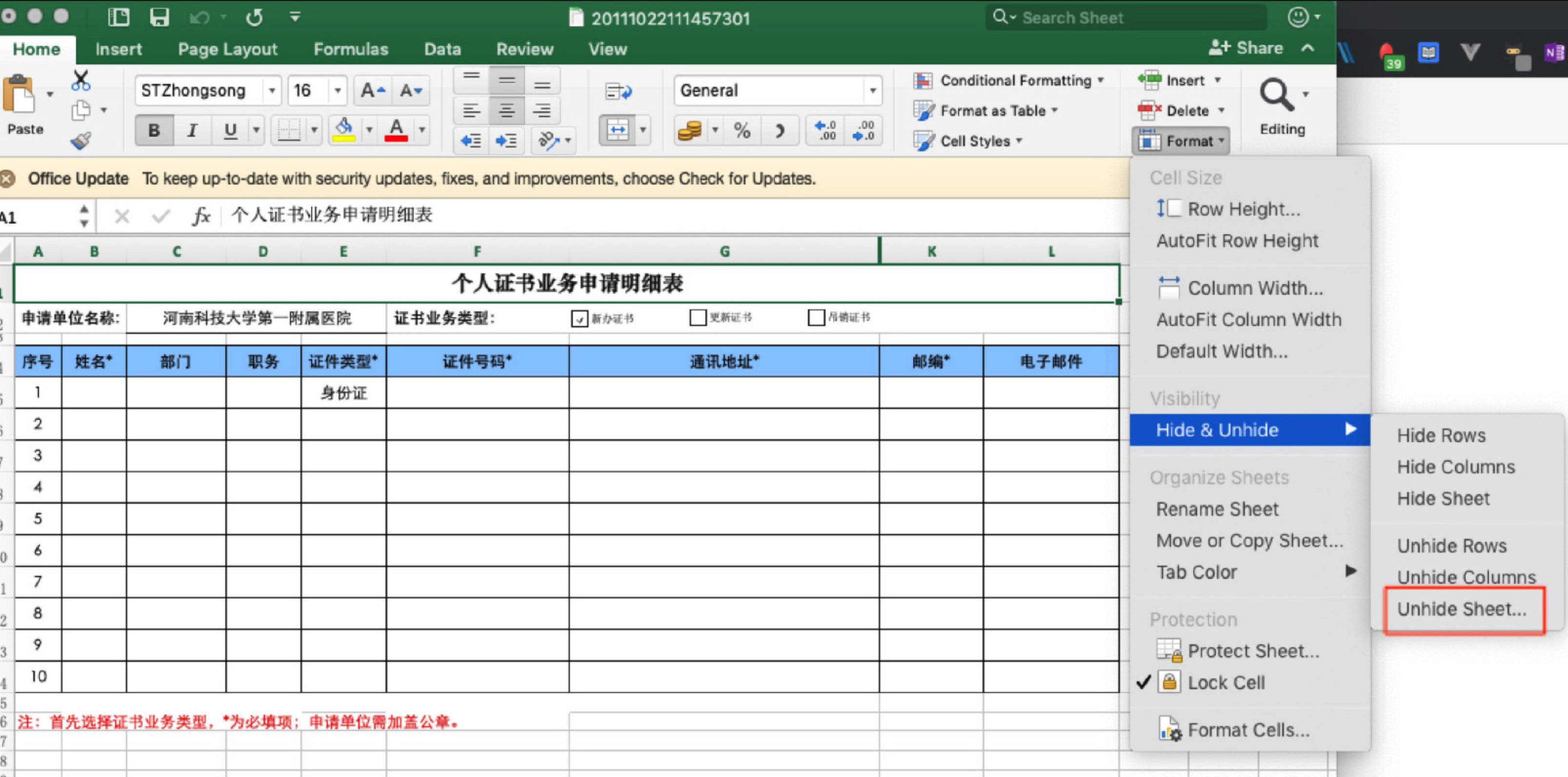
-
excel的折叠列:
拉开前:

看图上的绿色线,是把内容折叠了起来
实际上把绿色线拉开之后,确实是存在敏感信息的.

在书里找到了敏感信息:
在一本书里,匹配到了邮箱…估计是作者、出版社的联系方式…
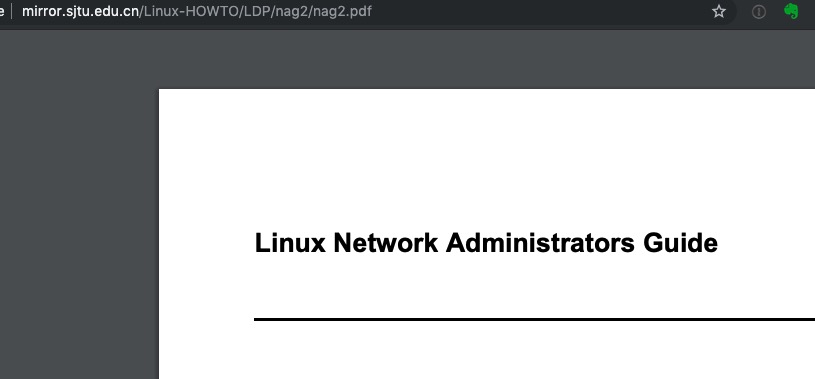
尴尬…
问题:
已解决的Bug:
把命令写死了:

不同环境下的python执行路径是不同的…
跨平台运行的问题:
比如wins下没有find命令,要用for
跨平台运行是个令人头疼的问题呀…会有很多意想不到的结果出现.
减少模板类文件的误报:
如模板类,解决办法: 通过数量判定,例如从某个文件收集到的邮箱少于2个.则认为这是个模板类文件.
举例:
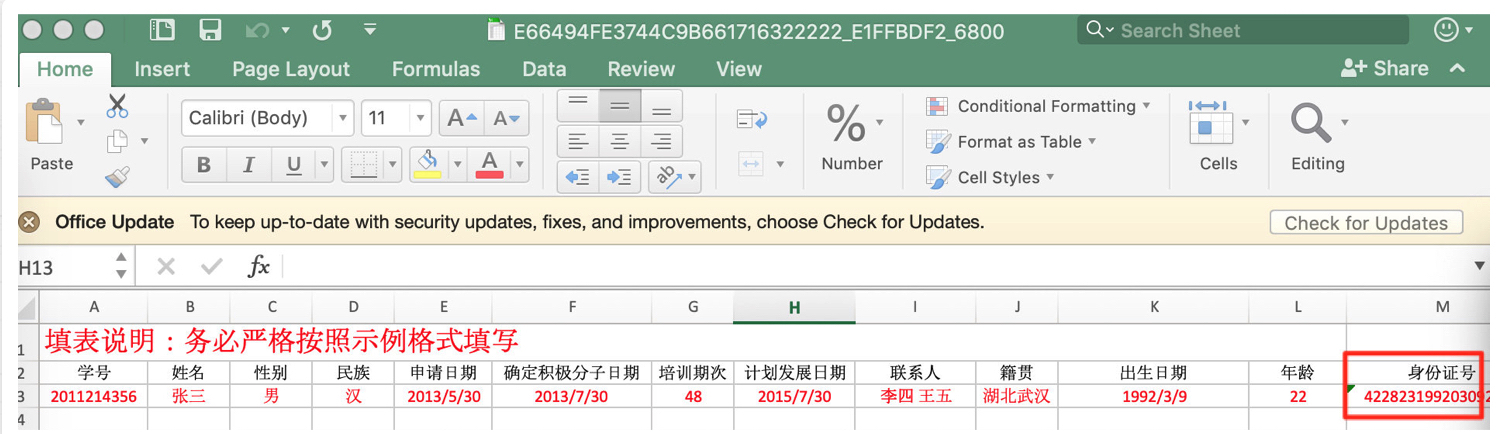
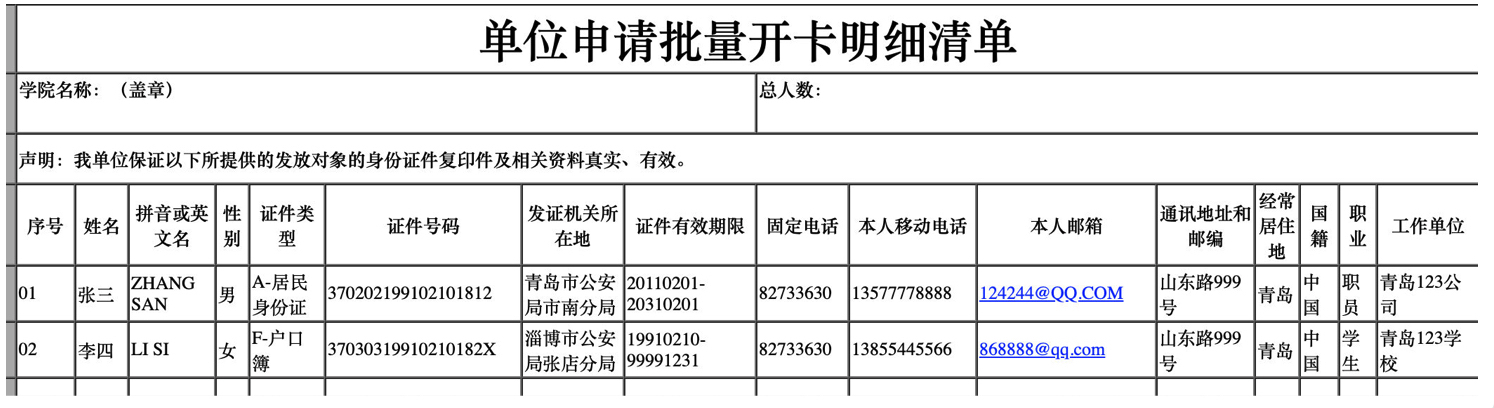
待改进的地方:
更多的正则匹配:
for Chinese:
-
支付宝账号
-
社保账号
-
银行卡号
-
身份证
-
护照
-
香港永久性居民身份证
-
澳门永久性居民身份证
-
台湾居民来往大陆通行证
-
军官证
for Foreign:
-
外国手机号
-
外国身份证号码
估计也没时间去完善hhh
基于关键字匹配:
-
身份证
-
身份证号
-
身份证号码
-
身份证件号码
-
证件号码
-
zjhm
-
证件类型
-
证书号码
-
手机
-
联系电话
-
联系方式
-
电子邮箱
-
dzly
-
通信地址
-
家庭地址
预期使用关键词匹配的话,误报会很多,只适用于excel类型的表头.
动态链接下载:
-
http://yjsy.uibe.edu.cn/common/downloadFile.jsp?id=119295 -
http://yz.nwafu.edu.cn/common/rtfeditor/openfile.jsp?id=DBCPDBDDDFDIDBCPDADBDGCOHIGMHD
类似以上这种url,要访问动态链接,服务器才会返回文件的url地址.
目前是处理不了这种情况.
搜索引擎是可以爬取到这类url的文件的预计解决办法是:1.要用上无头浏览器等技术.模拟发包是不行的 2.直接访问该url并下载文件.
其他:
测试服务器:
跑到机子模糊…
搜索引擎hack:
百度:
site:*.edu.cn filetype:xls
site:*.edu.cn filetype:xls 身份证
google:
site:*.edu.cn filetype:xls
主要是用于前期寻找测试文件
注意点:
我已知的,目前edu-src判定是敏感文件的范围是:
-
个人手机
-
个人住址
-
个人邮箱(目前不收了) -
身份证
不属于的范围:
-
工作邮箱
-
准考证号
知道规则也很重要…hhh
修复方案:
-
作为信息公示的话,身份证显示后六位或者打码显示即可
-
如无必要,不要上传到公网上.
Contributors:
-
JackChan1024
hacking together , is so cool…
refs:
-
not-your-average-web-crawler 这是个很棒的爬虫框架.