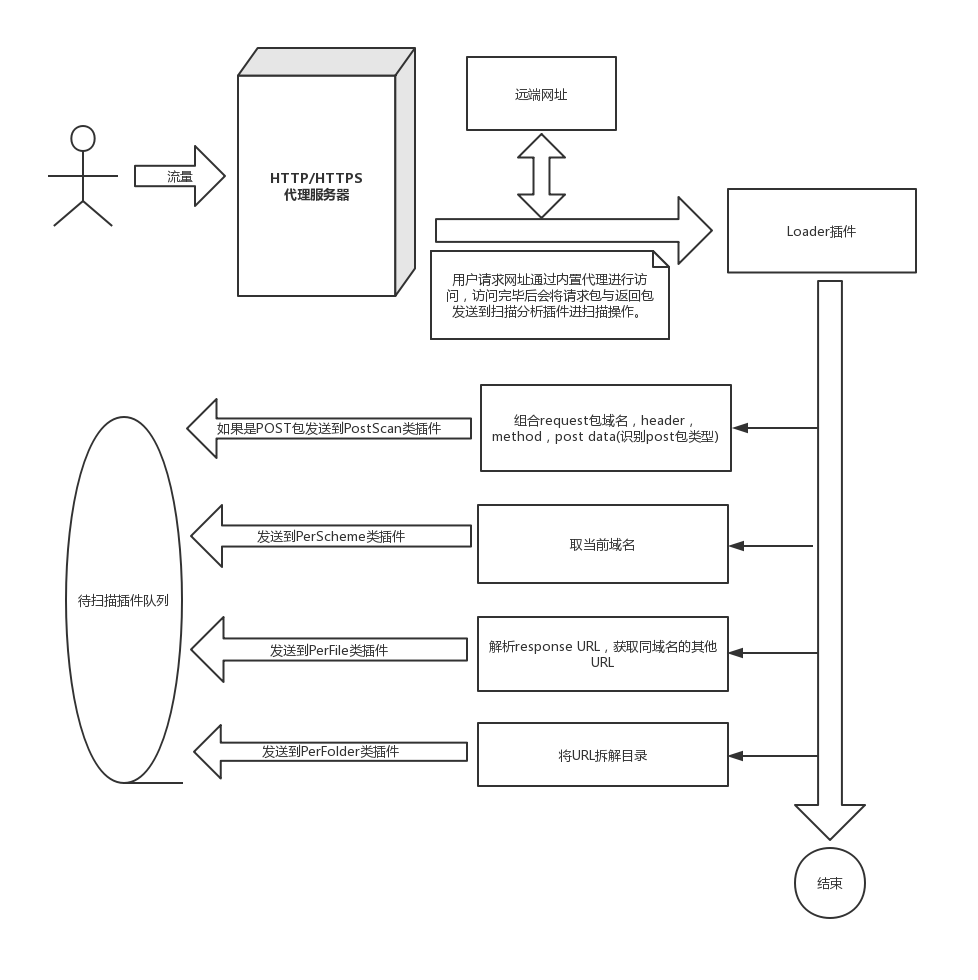
整体流程图
PerFolder (每个目录)
比如有一个url为:http://xxxxxxxx/imcloud/static/seat/build/images/pic.jpg
拆解后的目录为:
1 | http://10.125.20.39/ |
然后以这些目录url为基础,拼接url去扫描
备份文件扫描:
原理:
获取来自服务器的原始套接字响应即通过文件头来识别。
1 | r = requests.get('https://api.github.com/events', stream=True) |
上网找了一个rar,试了一下输出的文件头是b'PK\x03\x04\x14\x00\x00\x00\x08\x00'
插件里的注释
1 | * rar:526172211a0700cf9073 |
不同后缀的文件有不同的文件头特征.
有一份简单的备份文件的字典列表,'bak.rar', 'bak.zip', 'backup.rar', 'backup.zip', 'www.zip', 'www.rar', 'web.rar', 'web.zip', 'wwwroot.rar', 'wwwroot.zip', 'log.zip', 'log.rar'
字典这玩意可大可小
通过拼接url,如果status_code是200而且文件头符合,则判断为扫出了备份文件。
目录遍历:
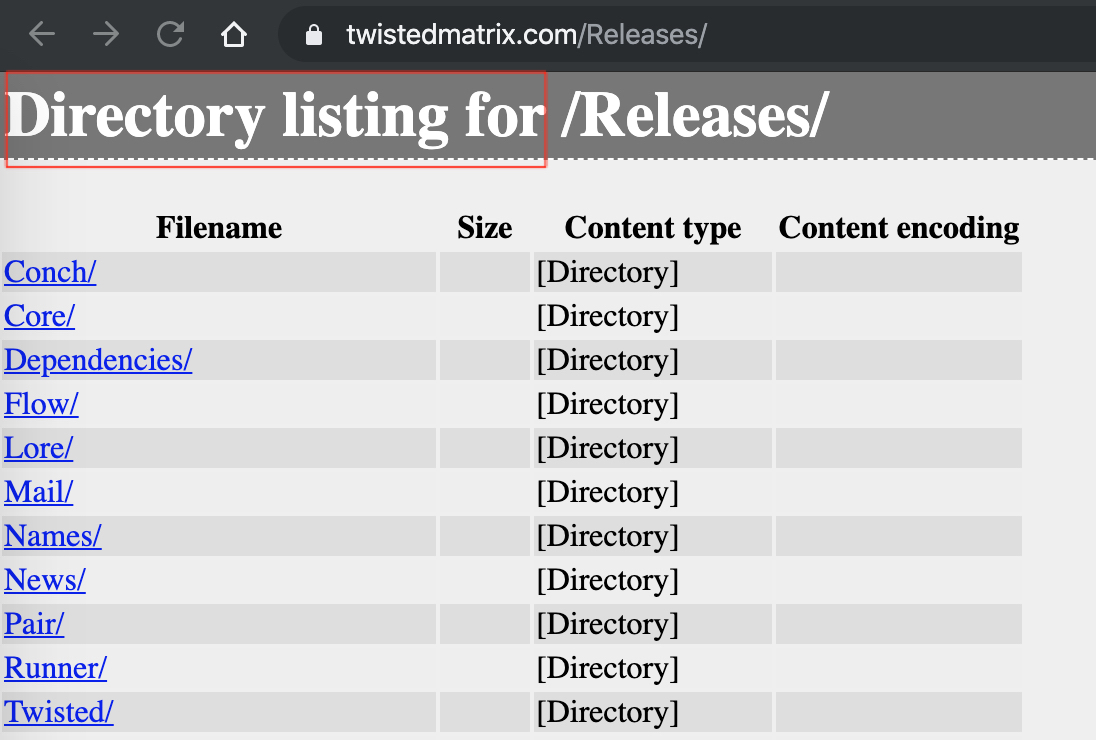
找出一些常见的目录遍历的页面,html源码中有这些特征
1 | "directory listing for" |
如果在返回包的源码中发现这些特征,则判断这个页面有目录遍历漏洞。
敏感文件扫描:
敏感文件字典采集于bbscan
总的敏感文件有以下这些
1 | /config.inc |
实际上的字典的格式为{'path': '/config.inc', 'tag': '', 'content-type': '', 'content-type_no': 'html'}
-
tag: html源码特征 -
content-type: 文件拓展名 -
content-type_no: 文件拓展名黑名单
原理:
拼接url,发包访问,返回码为200且同时满足以下3种条件
-
符合html源码特征
-
符合文件拓展名
-
不在文件拓展名黑名单
.idea 工作目录解析:
原理:
url拼接上/.idea/workspace.xml
如果返回包源码中能正则匹配到<project version="\w+">,正则匹配版本号,则判定为 JetBrans .idea 泄漏.
phpinfo探测解析:
字典为
1 | "phpinfo.php", |
原理:
拼接Url,发包访问,如果返回包中含<title>phpinfo()</title>, 则判定为存在phpinfo文件
git svn bzr hg泄漏:
字典为
1 | flag = { |
键为文件路径,值为正则匹配规则。
拼接url, 正则匹配返回包内容,匹配成功则判定为目录下有仓库源码泄漏漏洞
Sftp探测:
字典:
1 | /sftp-config.json |
正则匹配
("type":[\s\S]*?"host":[\s\S]*?"user":[\s\S]*?
"password":[\s\S]*"),(<Pass>[\s\S]*?<\/Pass>)
匹配到则认为找到sftp
WEB编辑器探测:
规则格式和判定方式和敏感文件扫描一样。
规则格式:{'path': '/fckeditor/_samples/default.html', 'tag': '<title>FCKeditor', 'content-type': 'html', 'content-type_no': ''}
原理:
拼接url,发包访问,返回码为200且同时满足以下3种条件
-
符合html源码特征
-
符合文件拓展名
-
不在文件拓展名黑名单