Pre:
自己拍脑袋写了个idor_auto脚本去扫描越权漏洞。发现效果还可以。
上网查下资料整理下思路。
越权漏洞
简介:
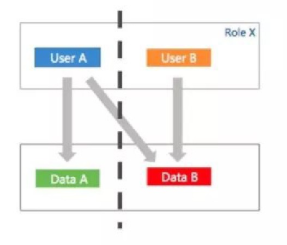
定义: 增、删、改、查,缺乏权限鉴定或者鉴定不严
分类:
-
未授权访问
-
水平越权
-
垂直越权
案例:

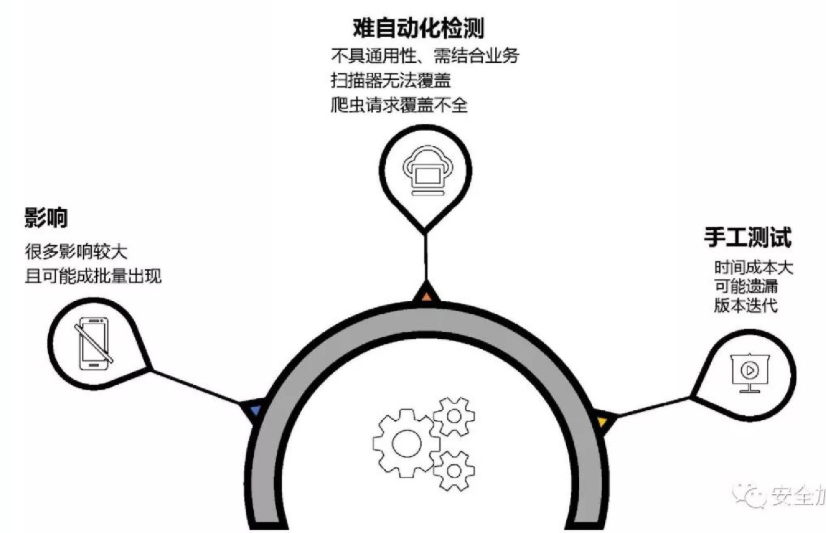
越权漏洞的痛点:
工具的设计思路:
第一版:
缺点在于要自己先找到某个包的某个参数是存在越权漏洞的,不够自动化。
第二版:
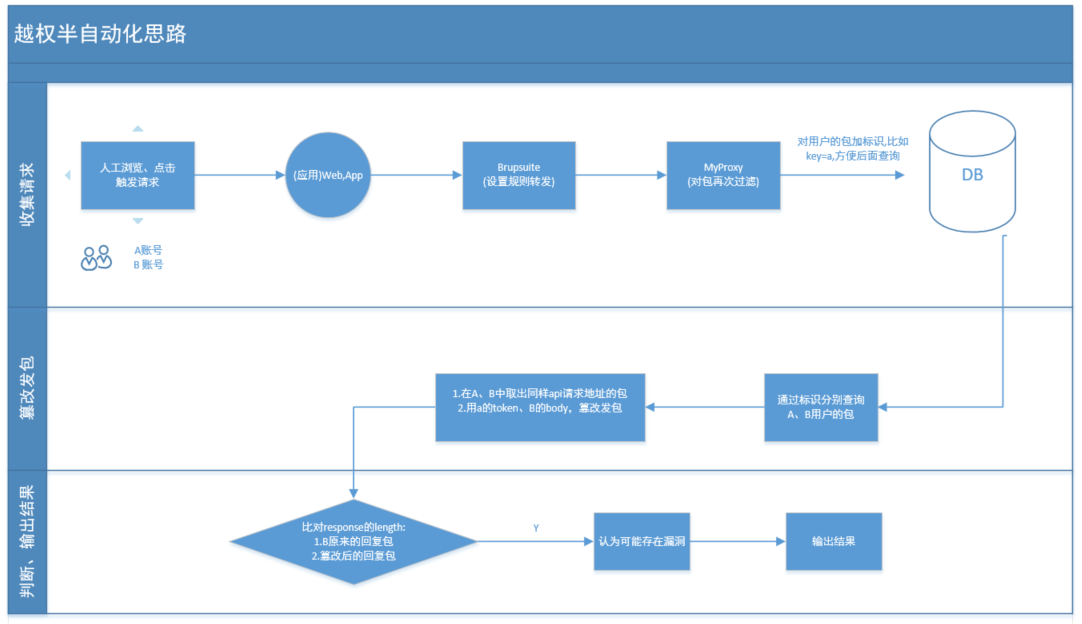
输出的结果:

相对第一版来说,更通用。自动化程度更高
缺点:需要2个账户在登录下,尽可能多的点击相同的功能点,触发请求,效率有点低。
存在误报的情况:
比如公共接口:
用两个账户的token去请求链接可以得到同样的响应结果,但是该页面本身没有数据操作的功能。
可以理解为这类结果为公共接口,例如 获取地区省市县的接口,获取最新更新包的下载地址接口。
不管用谁的token获取的结果都是一样的。
参考别人的思路:
ele:
思路设计1:Request重放

缺乏鉴权的部分,图中的用法是单纯替换token,而我的工具的做法是,替换整个请求body。
单纯替换token的粒度更低,相比我的方案可以发现更多:在url上的越权,一些头部字段的越权,这感觉效果更好。
而且,可以只需要用单一用户点击功能,触发请求就可以了。相比我的方案(两个账户触发请求)来说,效率更高。
修改ID的部分,感觉不能单纯的对数字加一减一,效果不好,比如说订单号order_id,加一减一之后不一定是真实存在的订单号。
过滤部分,过滤掉本身无需鉴权的请求,这一点可以大大减少误报。
思路设计2:Response比对

比较body的内容是否完全一样,这样会漏报。因为有些response里面含有一些随机值。
比较body length的话,可能会误报,但是总比漏报好。
比较好的比对方案是: status code + body length
中通scr:
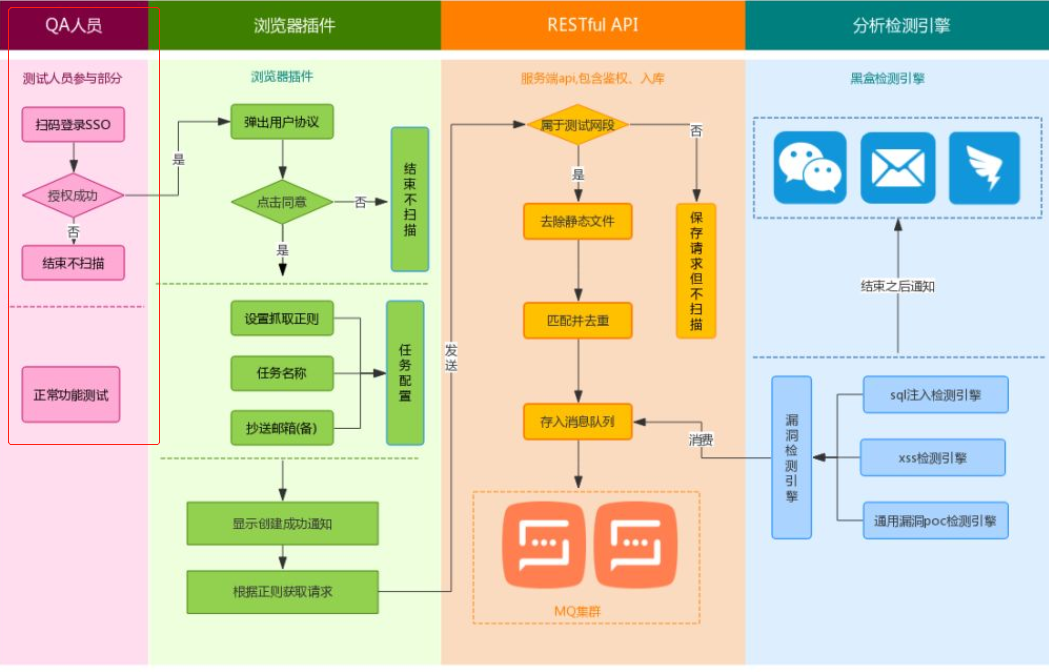
开发了浏览器插件供QA人员使用,触发请求部分不需要由安全的同事来做,这一点很赞。
首先我们来看,越权漏洞的本质是服务方没有正确地进行鉴权,如果能够准确无误地执行了鉴权的动作,那就不会存在越权漏洞。这里有一个前提就是合理的权限设定,判断是否正确地执行了鉴权,其实就是判断真实的响应结果是否和规划的权限设定里测试用例的预期结果是否一致,如果一致那就不存在越权漏洞,反之则存在,以上是整个方案的基础原理。
其次在工程上如何实现呢?要获取真实的响应结果和规划的权限设定,需要六个实体的参与:安全测试人员、检测应用、部署检测应用的设备、统一认证中心、统一权限中心、统一资源中心,关键点在于自动化地安全认证(安全测试人员登录检测应用的身份认证和检测应用作为独立身份与其它实体的应用间的认证)、自动化地获取被测系统包含的所有权限列表并授权(检测应用从统一权限中心拉取后以安全测试人员的身份请求权限中心进行逐一授权)、自动化地获取被测系统的所有对外服务及对应的包含预期结果的测试用例(服务及测试用例作为资源被自动化地解析到统一资源中心,检测应用从统一资源中心自动拉取),检测应用在通过相关认证和授权后可以自动化地按照拉取的服务列表执行对应的测试用例并进行判断,然后自动化地取消上一个授权获取下一个授权直到结束。
由于自动化授权的敏感性,可以由检测应用和部署检测应用的设备结合成网络代理并且由安全测试人员提供TOTP满足信任要求,另外测试用例要做到生产环境的无害性,这样也可以直接部署到生产环境进行定期自动化测试。接下来对部分细节作简要阐述,在传统开发模式中,系统规划的权限设定通常存在开发人员的大脑和服务的鉴权代码中,这样非常不利于上线前权限设计的合理性和正确性的评审以及上线后鉴权逻辑实现正确性的核查,也是越权漏洞频发的根因,我们需要在服务开发之初就文档化下来,包括服务的定义、安全测试用例及预期的结果,在开发实现方面,我们可以借助流行的IDL接口描述语言的一些特性,如protobuf的descriptor或option,IDL用来定义服务,其中的一些特性用来定义安全测试用例及预期的结果,结合起来可以支持非常复杂的场景,服务方面既可以提供RPC也可以提供RESTful形式,意味着既可以支持中台对外服务也可以支持对内的微服务(对内的微服务作为独立的身份实体),安全测试用例方面既可以支持行为、菜单等权限,也可以支持数据权限,整个的定义如proto文件需要自动化地解析到资源中心并且和应用标识关联起来。另外在统一权限中心的设计方面,我们需要将应用所有的权限集中配置和使用,并且做到配置项和服务的关联,这样可以实现任意权限模型的支持,如RBAC、ABAC等。
这个零信任安全架构下的全新思路有点东西。。。
构思:另一种更好的方案:
半自动化的原因是因为触发请求的部分最好是由人来触发。这样能保证请求的真实、多和全。
甲方的话可以通过查询api的日志来做到这一点。
api日志里面的请求是完整的,真实的,是由用户触发的。
比如查询最近10分钟的api日志,就可以拿到多个用户的有效的真实请求。
然后进行测试,首先这样就做到了在收集数据包方面的自动化,不需要再一个个的去点了。
但是这样的话,有个需要考虑的点:如果是在生产环境,很容易出现给其他用户写入脏数据
怎么样保证无害化?又是一个值得考虑的点。比如用生产环境的日志(生产环境的日志可能又不够全)。
其他问题:
增删改查
查是最容易实现的,那么增删改呢?
没有数据
有些接口,如果你的2个测试账户都是没有数据的话,往往测试账号都是没有什么信息的。
那么不管怎么测,他们的结果都是空的,没有什么意义的数据。
这个时候在实际的渗透测试中,比如phone参数,你会用特制的手机号列表去遍历,直到一个length特别不同的包出现,这个时候才能真正的证明这个接口是有越权的。