Pre:
上篇提到,最终定下的方案是,租用大厂(Google cloud、Amazon aws、Vultr)等的海外云gpu服务器,那开始在这些厂商租用服务器。
在租用过程中,也碰到了不少的问题。
动态租赁方案:
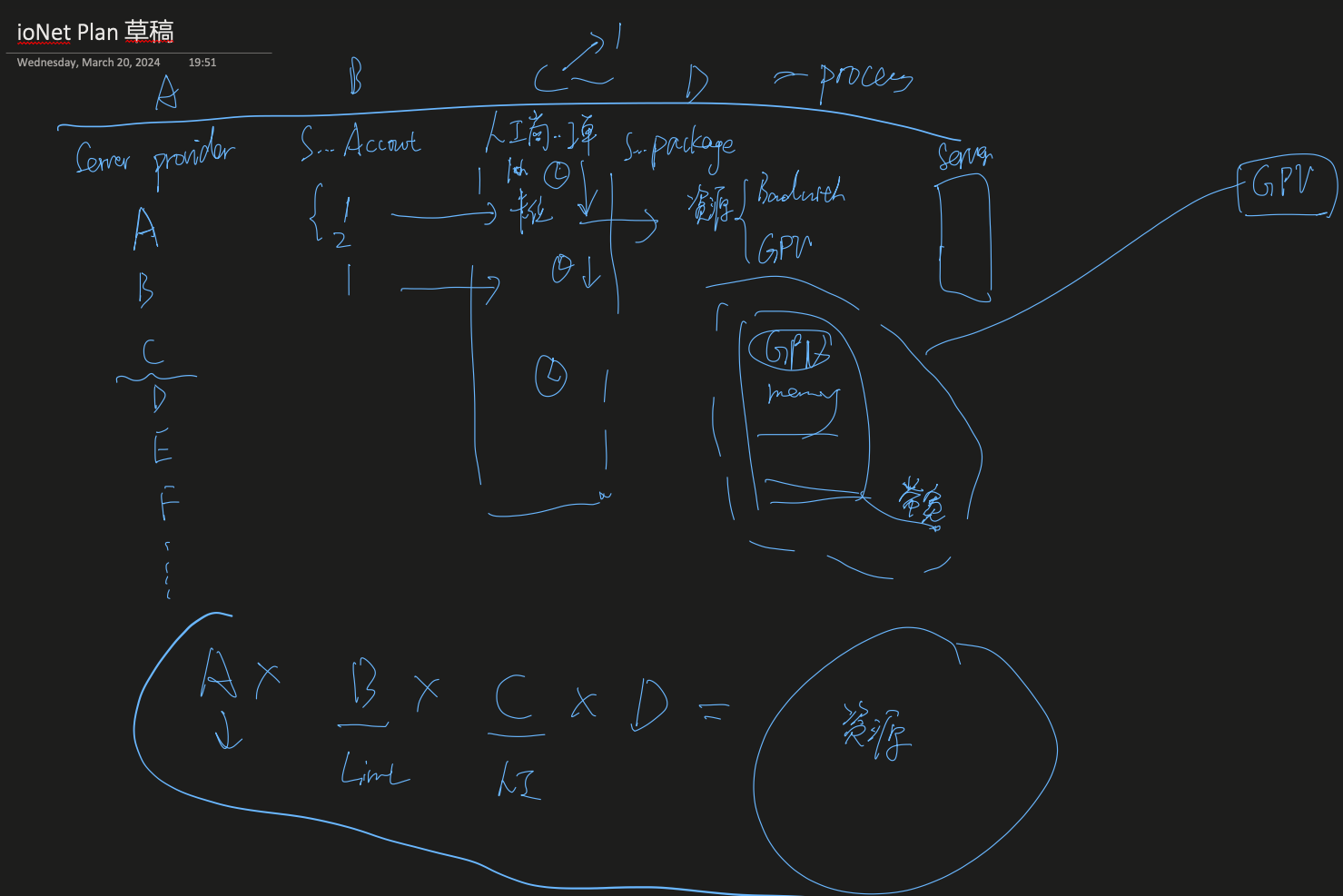
在租用云服务器过程中,有以下变量:
-
server provider
-
server Account
-
人工沟通、工单
-
服务器配置
初步定的是一个动态的方案,哪家云服务器厂商提供了算力,就优先上部分算力,与此同时,由于是租用的方式,到时候也可以动态地把部分算力下线。
Vultr:
Vultr上有a100,a40,a10系列的机器,性价比都不错。但遇到的问题是,账号有购买限额。
新号是250u/月,为了租用足够的云服务器,有2个思路:
-
申请多个Vultr账号
-
单个大号,以企业采购的名义与客服进行沟通
多号:
在测试过程中,采用英国手机号及认证信息的话,新注册的号,官方会给到500u/月的额度。如果用Chinese的认证信息去注册的话,只能开到250u/月的额度。
注册多个账号,有以下缺点:
-
ip地址与认证信息不一致,容易被封号,不稳定
-
多个账号下,不利于管理机器
考虑到以上因素,不按这个思路去执行。
客服沟通:
提交工单,以公司的名义与Vultr官方进行沟通,表面我们是企业用户,有较大的预算,可以预付服务器费用,希望在它上面采购租用较多的云gpu服务器。
经过多次工单后,对方只是将我们大号的额度,由250u/月提升到750u/月,并且表示如果需要提额,只能等下个月。
那么这条路也走不通,存在不可控因素:
-
账号有限额
-
a系列的卡数量有限,就算有额度,也不一定有货
所以只能放弃Vultr。
Oracle:
Oracle的机器配置太大,过于冗余了,而且价格很贵。
当中有个小插曲,另一位技术小伙伴觉得可以尝试在Oracle的一台机器上,采用虚拟化的方式,将1个gpu虚拟化成多个gpu,以作弊的方式在一台机器上跑多个Worker。
当时我查了下,docker是可以获取到宿主机的硬件信息,也就是说ionet官方有办法检测到此类的作弊方案,就否了这个思路。
后来事实证明这个思路确实不行,因为ionet官方出了公告,说要严格检测作弊的Worker。
Amazon aws:
在aws上,决定购买的是T4的卡,也是遇到了同样的账户限额的问题。这类云厂商的付款方案都是先用后付,采取的是一个信用分的机制。
对于新号,信用分低,也是有对应的限额,但是亚马逊在国内有一定的团队,可以很快的就和他们的官方人员沟通上,并且打开了限额。
后续还和他们的BD人员进行了沟通,了解到了亚马逊在国内,大多都是走的经销商的方案,也就是个人预付款给经销商,经销商给机器给个人,到时候官方找经销商收款的模式。
走经销商方案的话,有以下优缺点:
-
优点:付款方便,有些经销商支持usdt支付,可以快速开机器,没有限额的限制
-
缺点:需要预付款,也就是要先打一大笔钱过去
考虑到多个因素,一方面是资金方面不安全,个人不太信任第三方公司,一方面是价格没有太大的折扣,约9折左右,一方面是打钱过去后,这部分算力的额度就要锁定在亚马逊上,到时候想切换部分算力到别的云服务器厂商的话,就没有操作空间了。与一开始指定的动态方案相违背。
所以,就没走经销商方案,直接在官网用自己的账号购买。
当中遇到一个小插曲就是,官方的付款方式非常麻烦,仅支持电汇的方式,需要以公司名义走公账,银行汇款,一直搞不懂该如何电汇。在与aws销售沟通的时候,对方存在一定的错误引导,一直推荐我们走经销商方案,当时我怀疑销售是为了吃下其推荐的经销商给的回扣。
后来到下个月扣款日的时候,发现官网上绑定的信用卡能够成功扣款,才结束了和aws销售扯皮的沟通。
当时人手不够,没有及时去跟进服务器成本的计算,在aws上开了将近20台t4的机器,过了几天去算了一下,不算不知道,一算吓一跳.
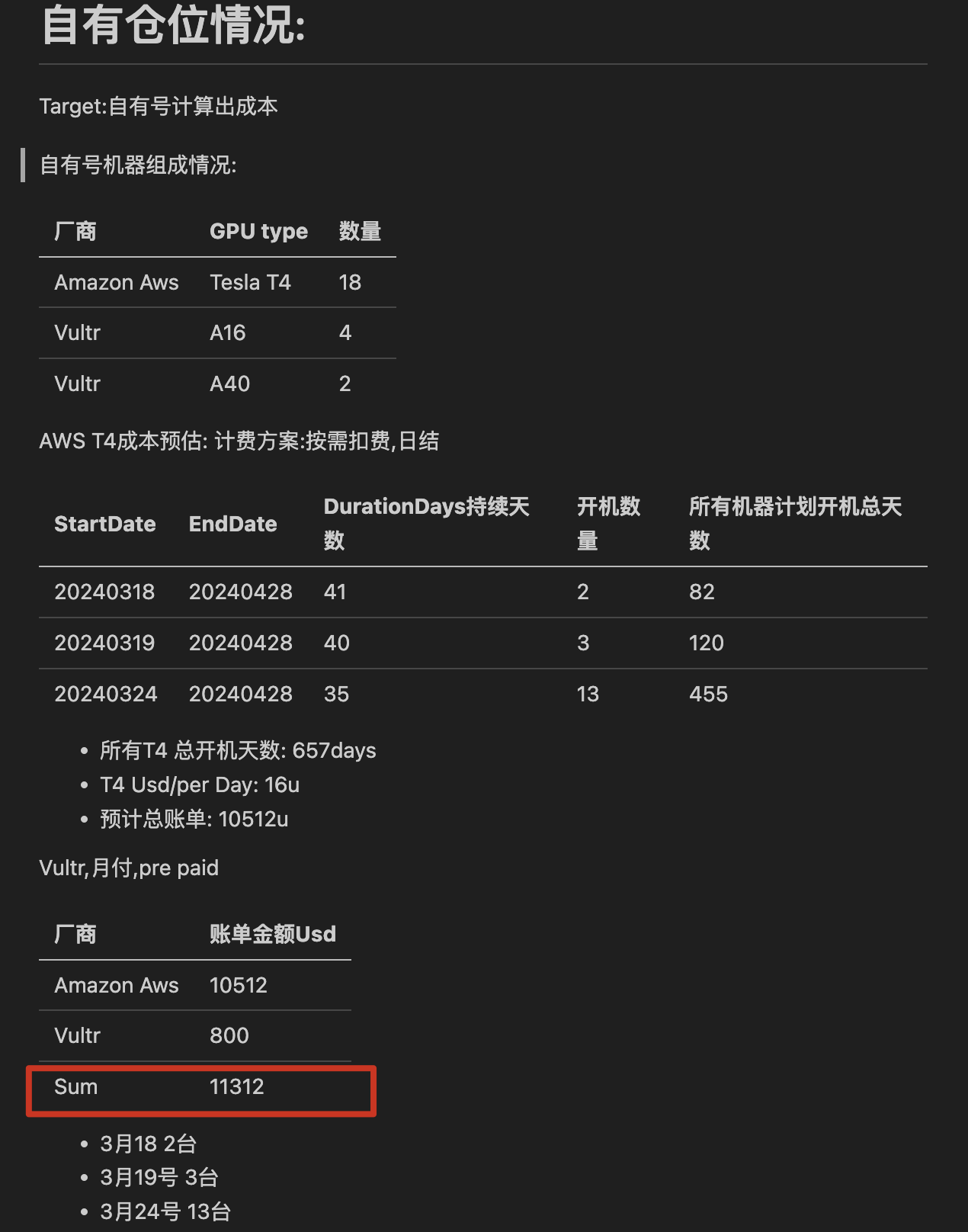
预计总账单达到11000多u,吓得我赶紧把aws上的机器都停了。
至此,需要找到新的替代方案。
市面上竞品方案:
竞品一: 龙哥_Google_T4_525u:

竞品二 五哥_Google_T4_350u:

在跑算力的过程中,发现ionet的客户端占用资源很少,也就是空挂状态下,按照官方文档给出的最低配置去跑的话,很浪费服务器资源。
再结合市面上的竞品方案,别的团队在Google cloud配置的云算力成本较低,后面决定用更低的服务器配置去跑ionet,因为其空挂状态下用不了啥资源,开始研究如何把算力切换到Google cloud上。
Google Cloud:
个人账号在Google Cloud上同样是有限额问题,如果需要开较多的gpu服务器,也是需要走人工申请。与亚马逊云不同的是,Google cloud没有国内的同事,在沟通上只能通过邮件的形式。
邮件的沟通时效性就很差了,由于着急上机器,同时自己也去找一下经销商。
让之前的aws销售推荐一家Google cloud经销商,给的价格也是没有什么折扣。
货比三家,自己去Google一下,国内有什么较大的经销商,后来找到了一家挺不错的厂商Cloud Ace。
联系上对方的国内团队后,对方还推荐了另一个gpu型号:L4的机器,还给了定制化的套餐,感觉对方挺专业的,服务器价格方面也非常不错,大概是160u左右一个月。所以剩余的25天左右的算力就全上到他们家了。
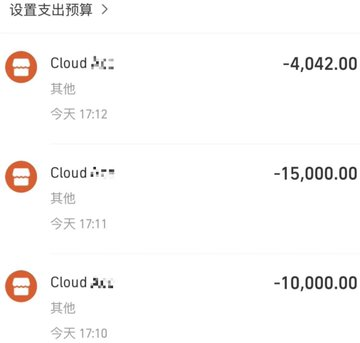
也再次印证了,那位aws销售不太ok。
至此,租用算力的方案没有优化的空间了,折腾算力租用的过程也告一段落了,后面就是持续维护Worker的上线情况了。