Pre:
当一个事情变得枯燥时,就该考虑自动化了。
场景:当你渗透测试一个网站时,你发现其中某个页面某个参数存在越权时,你就会想那么其他页面的其他包的这个参数会不会有问题。。。
可是又要全测一边会觉得累,不测又会觉得漏。那这个时候就可以考虑下自动化,半自动化了。
我就尝试在w13scan的架构下,编写了一个简单的越权半自动化插件
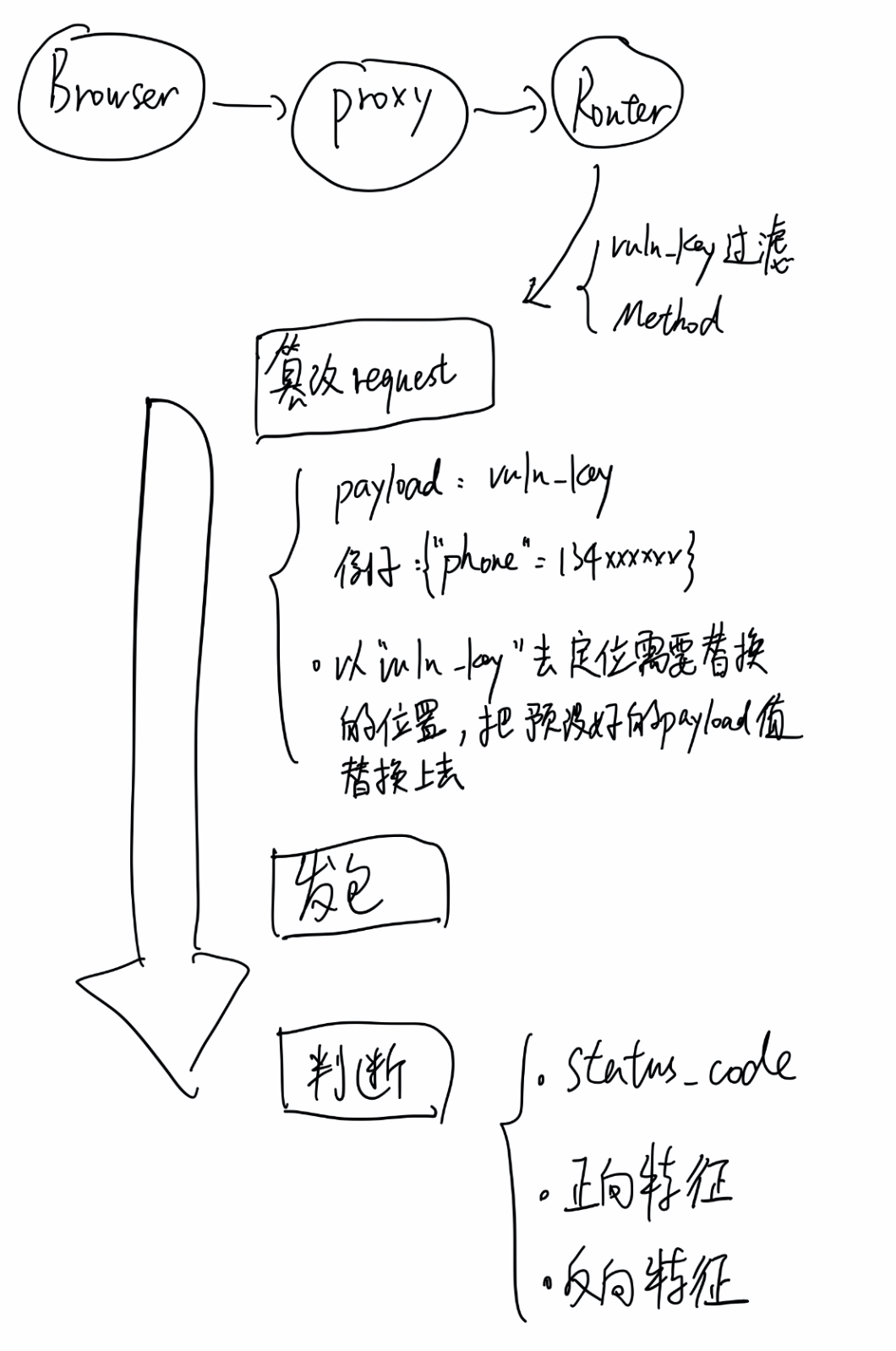
流程:
第一步:手工测试找vuln_parameter
先是手工测试出某个包的某个参数是存在越权漏洞的,也就是这个参数值可能服务器没有做很完备的鉴权。
比如是phone这个参数,那么以这个作为vuln_key(vuln_parameter)
第二步:以vuln_parameter做路由
就是含有vuln_parameter的包,都会路由到这个插件里进行处理
第三步:确定payload
比如是phone参数,然后准备另一个用户的手机号码
确定payload: {"phone":134xxxxxx}
第四步:篡改request包
以vuln_parameter去定位包中要篡改的位置,然后将准备好的payload的参数值替换上去.
第五步:发包,权衡判断条件
判断我感觉比较麻烦:
可以通过status_code状态码,Response状态码为200的话可以先保证:篡改的过程中的请求参数没有出错。
然后再加上一个And的条件:正向特征、反向特征
-
正向特征:
先收集一些请求成功且有返回一定数据的Response包
例如Response的body里:
1 | {'msg':'OK', data:{"name":xxx, "address":xxx}} |
-
反向特征:
收集一些请求成功但是服务端有鉴权判定为越权的Response包
例如Response的body里:
1 | {'msg':'你没有权限进行此操作', data:null} |
1 | {'msg':'不可以越权操作', data:{}} |
1 | {'msg':'xxxxx', data:false} |
从正反两个方面去提取一些特征,作为判断是否有越权漏洞的标志。
比如
正向的就是 :
1 | if status_code =200 and response['msg'] == 'OK' |
反向的就是 :
1 | if status_code =200 and response['data'] is not null |
判断的效果 跟判断条件有很大的关系判断严了,容易漏 判断松了 容易误报那么我觉得比较好的判断原则是: 宁可误报,也不要漏
大致流程图:
效果图:
效果不是很理想,一开始以为可以找到更多处地方的越权漏洞,结果只能验证到原来手工能测出来的那个越权点。
但是好处就是,你确定这个vuln_parameter在其他页面确实是没问题的。
这个思路是大致ok的,之后再优化下,在别的系统上应该能有比较好的效果。
总结:
-
半自动化流程:
-
手工测试找
vuln_parameter -
以
vuln_parameter做路由 -
确定payload
-
篡改request包
-
发包,权衡判断条件
-
这种情况下是只持有单用户的token,如果有两个用户的token和更多的数据包,判断效果会更好
-
只适用于平行越权,普通用户a越权查看普通用户b的信息,只能做查的操作,增删改的操作貌似做不到。
-
每换一个
vuln_parameter就要修改一下脚本,可考虑修改的地方作为变量,但是因为w13scan架构的关系,暂时好像不支持插件中含有变量